
ขั้นตอนการฝึกอบรมแบบ end-to-end บนโมเดลภาษาขนาดใหญ่ LLM-13 Billion GPT โดยใช้ Spasity และ Dataflow
การนำระบบแมชชีนเลิร์นนิงไปใช้ในด้านวิชาการและการค้าได้รับการเร่งความเร็วโดยโมเดลพื้นฐานในโดเมนการประมวลผลภาษาธรรมชาติและการมองเห็นด้วยคอมพิวเตอร์ นักวิจัยได้แนะนำให้เพิ่มจำนวนพารามิเตอร์ตามลำดับความสำคัญเพื่อดึงความสามารถเพิ่มเติมจากโมเดลเหล่านี้และฝึกฝนคลังข้อมูลจำนวนมหาศาล คุณสมบัติหลักในการควบคุมตนเองและความสามารถในการปรับตัวทำให้สามารถพัฒนาแอปพลิเคชันได้หลากหลายเพื่อแก้ไขปัญหาเฉพาะ รวมถึงการผลิตข้อความ การวิเคราะห์ความรู้สึก การแบ่งส่วนรูปภาพ และการจดจำรูปภาพ
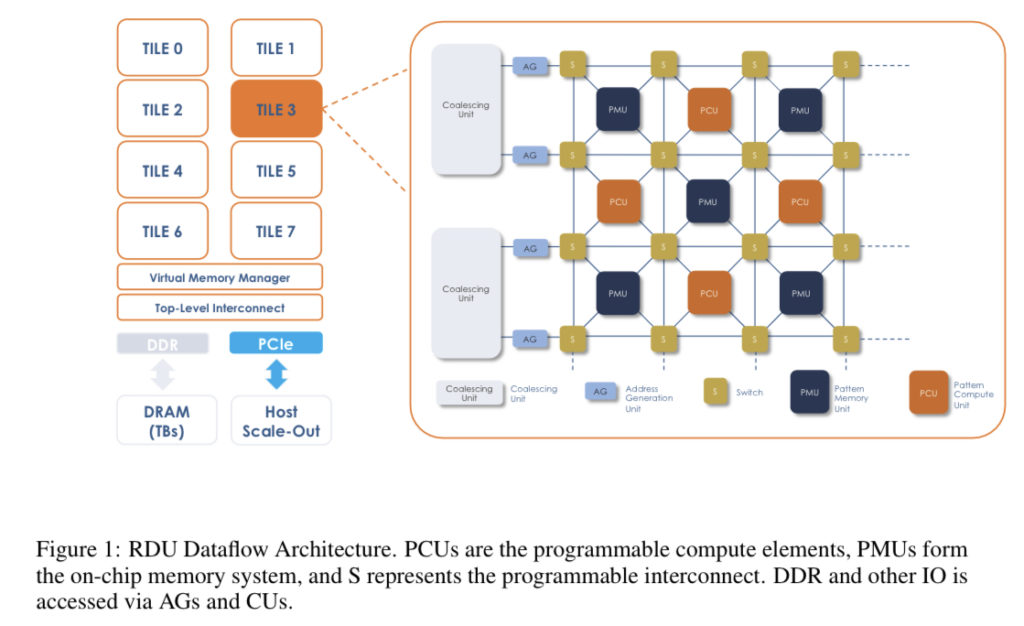
รูปที่ 1: สถาปัตยกรรม RDU Dataflow PCU เป็นองค์ประกอบการคำนวณที่ตั้งโปรแกรมได้ PMU สร้างระบบหน่วยความจำบนชิป และ S แสดงถึงการเชื่อมต่อระหว่างกันที่ตั้งโปรแกรมได้ DDR และ IO อื่นๆ เข้าถึงได้ผ่าน AG และ CU
เนื่องจากข้อจำกัดด้านพลังงานและทางกายภาพ ฮาร์ดแวร์พื้นฐานที่ใช้ในการฝึกโมเดลขนาดมหึมาดังกล่าวจึงจำเป็นต้องปรับขนาดตามสัดส่วนของพารามิเตอร์โมเดล มีการตรวจสอบเทคนิคหลายอย่างเพื่อเอาชนะความท้าทายด้านการคำนวณนี้ รวมถึงการปรับโครงสร้างเครือข่าย การตัดเครือข่าย การกำหนดปริมาณเครือข่าย การกลั่นความรู้การสลายตัวระดับต่ำ การกระจายตัวของโมเดล เป็นต้น วิธีการแบบกระจายประเภทต่างๆ ถูกนำมาใช้เพื่อลดความเข้มของการประมวลผลและเลียนแบบการเชื่อมต่อ ระหว่างเซลล์ประสาทในสมองของมนุษย์ สถาปัตยกรรมฮาร์ดแวร์พื้นฐานนำเสนอความยากลำบากใหม่ ๆ เนื่องจากวิธีการ Spassity ก้าวหน้าและมีการใช้กันอย่างแพร่หลายในแอปพลิเคชันการ
ฝึกอบรมและการอนุมาน (training and inference applications)
ระบบที่มีความสมดุลจำเป็นต้องทนต่อความผันผวนระหว่างการปรับใช้โมเดลที่โดยทั่วไปมีความหนาแน่นสูงในการคำนวณและหน่วยความจำที่กระจัดกระจายอย่างมาก เนื่องจากมีรูปแบบและขั้นตอนการฝึกอบรมที่เป็นไปได้มากมาย การคำนวณแบบกระจัดกระจายจึงต้องการความยืดหยุ่น ความสามารถในการตั้งโปรแกรม และประสิทธิภาพของฮาร์ดแวร์รุ่นต่อไป แทนที่จะเพิ่ม Tera-FLOP และแบนด์วิดท์หน่วยความจำเพื่อตอบสนองความต้องการด้านการคำนวณของการเรียนรู้ของเครื่อง การใช้วิธีการแบบเบาที่ดีในสถาปัตยกรรมที่เป็นมิตรสามารถช่วยในการเอาชนะอุปสรรคในปัจจุบันได้อย่างมีประสิทธิภาพ เช่น กำลังมหาศาล ต้นทุนเครื่องจักรที่สูง และเวลาการฝึกอบรมที่ยาวนาน
มีการนำเสนอกรอบการคำนวณมากมายเพื่อตอบสนองการเติบโตของการเรียนรู้ของเครื่องและแอปพลิเคชันปัญญาประดิษฐ์และคุณสมบัติโดยธรรมชาติ นอกเหนือจากสถาปัตยกรรมที่ใช้ CPU ทั่วไปแล้ว ตัวอย่างบางส่วน ได้แก่ Google TPU, NVIDIA A100 Nvidia, Cerebras CS-2, Graphcore IPU และ SambaNova RDU ขอบเขตทั้งหมดของความสามารถระบบฮาร์ดแวร์และซอฟต์แวร์เหล่านี้ โดยเฉพาะอย่างยิ่งในการจัดการแอพพลิเคชั่นที่กระจัดกระจายและหนาแน่นนั้นยังคงมีการค้นพบอยู่ แม้จะพยายามประเมินและเปรียบเทียบระบบเหล่านี้ไม่กี่ครั้งก็ตาม นอกจากนี้ เฟรมเวิร์กเหล่านี้จำนวนมากยังคงเป็นของเอกชนและไม่สามารถเข้าถึงได้สำหรับการวิจัยสาธารณะในโดเมนสาธารณะ แม้ว่าจะมีแนวโน้มดี แต่แนวทางแบบเบาบางก็มีปัญหาเพิ่มเติมนอกเหนือจากความเข้ากันได้ทางสถาปัตยกรรม
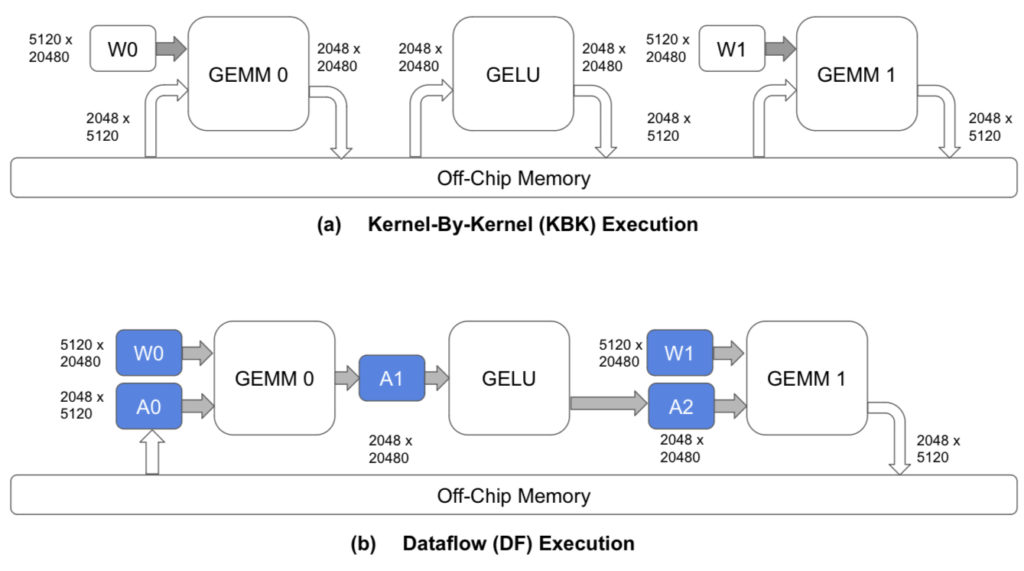
รูปที่ 2: การประมวลผลแบบ Kernel-By-Kernel (KBK) เทียบกับ Dataflow (DF) สำหรับตัวอย่างง่ายๆ ด้วย GEMM ตามด้วย GELU ตามด้วย GEMM ลูกศรสีขาวแสดงถึงทราฟฟิกไปยังหน่วยความจำนอกชิป ลูกศรสีเทาแสดงถึงทราฟฟิกบนชิป กล่องสีน้ำเงินแสดงถึงหน่วยความจำบนชิป กล่องสีขาวแสดงถึงทรัพยากรการประมวลผลบนชิป เราใช้มิติข้อมูลเมทริกซ์จาก GPT 13B ในตัวอย่างนี้ ขอบ / กล่องแต่ละอันมีป้ายกำกับขนาด Tensor ที่กำลังเข้าถึง
ความแม่นยำของแบบจำลองเฉพาะ ตรงข้ามกับค่าพื้นฐานที่มีความหนาแน่นเพียงอย่างเดียว ขึ้นอยู่กับปัจจัยหลายอย่าง รวมถึง sparsity ที่มีโครงสร้าง กึ่งโครงสร้างที่ไม่มีโครงสร้าง เปอร์เซ็นต์ของ sparsity weight/activation spasity และตารางการฝึกอบรม ต้องพิจารณาปัจจัยการตัดสินใจเหล่านี้เพื่อให้ได้มาตรวัดที่ทันสมัยที่สุดในโมเดลหนึ่งๆ ซึ่งต้องใช้เวลาและความพยายาม โมเดลภาษาขนาดใหญ่ ซึ่งอาจรองรับแอปพลิเคชันภาษาต่างๆ เป็นโมเดลพื้นฐานที่แพร่หลายในภาค NLP เช่น GPT พารามิเตอร์ 13B นักวิจัยจาก SambaNova Systems ในการศึกษานี้ใช้แบบจำลองนี้เพื่อแสดงให้เห็นว่าความกระจัดกระจายอาจรวมอยู่ในวงจรการฝึกอบรมแบบ end-to-end เพื่อให้ได้เมตริกความแม่นยำที่เทียบเท่ากันได้อย่างไร
พวกเขามีส่วนร่วมในวิธีการที่สำคัญดังต่อไปนี้:
• การตรวจสอบอย่างละเอียดว่าความสามารถในการกระจายข้อมูล การหลอมรวม และการไหลของข้อมูลมีปฏิสัมพันธ์กันอย่างไร
• การสาธิตการเร่งความเร็วเหนือ A100 โดยใช้ GPT 13B แบบกระจัดกระจายบน SambaNova RDU
• การวิเคราะห์สถิติการสูญเสียของโมเดล 13B GPT ที่กระจัดกระจาย การยิงเป็นศูนย์ และการยิงไม่กี่ครั้งเมื่อเปรียบเทียบกับพื้นฐานที่หนาแน่น
บทความนี้มีรายละเอียดเพิ่มเติมเกี่ยวกับการวิเคราะห์ของพวกเขา