เป็นข่าวดีสำหรับระบบโครงข่ายสำหรับส่งไฟฟ้า ที่กลัวว่า AI จะมีความต้องการพลังงานมากเกินไป
Potentially great news for a power grid in fear of AI over-demand

Google อ้างว่าเทคโนโลยีการฝึกอบรมโมเดล AI ใหม่ เร็วขึ้น 13 เท่า และประหยัดพลังงานมากกว่า 10 เท่า – JEST ใหม่ของ DeepMind ปรับข้อมูลการฝึกอบรมให้เหมาะสม เพื่อให้ได้ผลลัพธ์ที่น่าประทับใจ
Google DeepMind ซึ่งเป็นห้องปฏิบัติการวิจัย AI ของ Google ได้ตีพิมพ์งานวิจัยใหม่เกี่ยวกับการฝึกอบรมโมเดล AI ที่อ้างว่าสามารถเร่งความเร็วในการฝึก และประสิทธิภาพการใช้พลังงานได้อย่างมาก ตามลำดับความสำคัญ โดยให้ประสิทธิภาพมากกว่า 13 เท่า และประสิทธิภาพการใช้พลังงานสูงกว่าวิธีอื่นถึง 10 เท่า วิธีการฝึกอบรม JEST ใหม่เกิดขึ้นในเวลาที่เหมาะสม เนื่องจากการประเด็นเกี่ยวกับผลกระทบต่อสิ่งแวดล้อมของ AI data centers กำลังร้อนแรง
วิธีการของ DeepMind หรือที่เรียกว่า JEST หรือการเลือกตัวอย่างร่วม แตกต่างจากเทคนิคการฝึกโมเดล AI แบบดั้งเดิม ด้วยวิธีที่เรียบง่าย วิธีการฝึกอบรมทั่วไปมุ่งเน้นไปที่จุดข้อมูลแต่ละจุดสำหรับการฝึกอบรมและการเรียนรู้ ในขณะที่ JEST ฝึกอบรมตามชุดงานทั้งหมด ขั้นแรกวิธี JEST จะสร้างโมเดล AI ขนาดเล็กลงซึ่งจะจัดระดับคุณภาพข้อมูลจากแหล่งข้อมูลคุณภาพสูงอย่างยิ่ง โดยจัดอันดับแบทช์ตามคุณภาพ จากนั้นจะเปรียบเทียบการให้เกรดนั้นกับชุดที่มีขนาดใหญ่กว่าและมีคุณภาพต่ำกว่า โมเดล JEST ขนาดเล็กจะกำหนดชุดงานที่เหมาะสมที่สุดสำหรับการฝึก จากนั้นโมเดลขนาดใหญ่จะได้รับการฝึกจากการค้นพบของโมเดลขนาดเล็ก
บทความที่มีให้ที่นี่ ให้คำอธิบายที่ละเอียดมากขึ้นเกี่ยวกับกระบวนการที่ใช้ในการศึกษาและอนาคตของการวิจัย
นักวิจัยของ DeepMind ระบุไว้อย่างชัดเจนในรายงานของพวกเขาว่า “ความสามารถในการกำหนดทิศทางกระบวนการเลือกข้อมูลไปสู่การกระจายชุดข้อมูลที่เล็กกว่าและได้รับการดูแลอย่างดี” มีความสำคัญต่อความสำเร็จของวิธี JEST ความสำเร็จเป็นคำที่ถูกต้องสำหรับการวิจัยนี้ DeepMind อ้างว่า “แนวทางของเราเหนือกว่าโมเดลที่ล้ำสมัยโดยมีการทำซ้ำน้อยลงถึง 13 เท่า และการคำนวณน้อยลงถึง 10 เท่า”
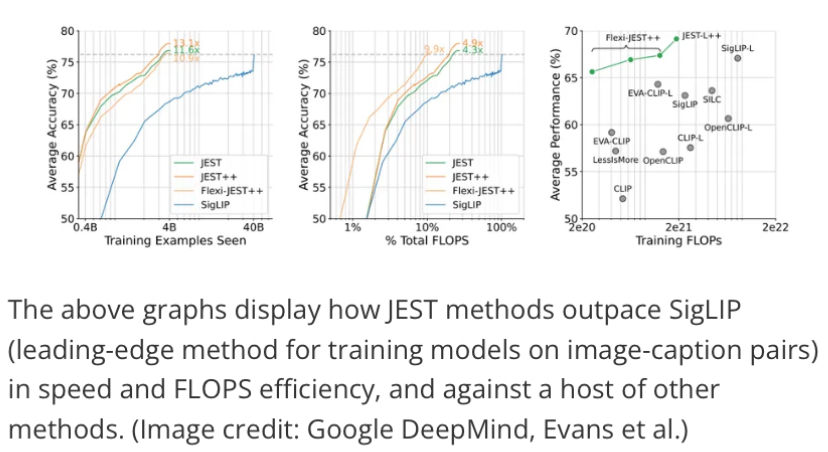
แน่นอนว่าระบบนี้อาศัยคุณภาพของข้อมูลการฝึกอบรมทั้งหมด เนื่องจากเทคนิคการบูตสแตรปแยกออกจากกันหากไม่มีชุดข้อมูลที่ดูแลจัดการโดยมนุษย์ที่มีคุณภาพสูงสุดเท่าที่จะเป็นไปได้ ไม่มีที่ไหนที่มีคติว่า “garbage in, garbage out“ ได้ชัดเจนยิ่งกว่าวิธีนี้ ซึ่งพยายาม “skip ahead ข้ามไปข้างหน้า” ในกระบวนการฝึกอบรม สิ่งนี้ทำให้วิธี JEST ยากขึ้นมากสำหรับมือสมัครเล่นหรือนักพัฒนา AI สมัครเล่นที่จะจับคู่ได้ดีกว่าคนอื่นๆ ส่วนใหญ่ เนื่องจากทักษะการวิจัยระดับผู้เชี่ยวชาญมีแนวโน้มว่าจะต้องใช้ในการดูแลจัดการข้อมูล initial highest-grade training data
การวิจัยของ JEST เกิดขึ้นไม่นานนัก เนื่องจากอุตสาหกรรมเทคโนโลยีและรัฐบาลโลกกำลังเริ่มหารือเกี่ยวกับความต้องการพลังงานที่รุนแรงของปัญญาประดิษฐ์ ปริมาณงาน AI ใช้เวลาประมาณ 4.3 GW ในปี 2023 ซึ่งเกือบจะเท่ากับปริมาณการใช้พลังงานต่อปีของประเทศไซปรัส และสิ่งต่างๆ ไม่ได้ชะลอตัวลงอย่างแน่นอน: คำขอ ChatGPT เพียงครั้งเดียวมีค่าใช้จ่ายมากกว่าการค้นหาโดย Google ถึง 10 เท่า และ CEO ของ Arm คาดการณ์ว่า AI จะกินพื้นที่หนึ่งในสี่ของตารางพลังงานของสหรัฐอเมริกาภายในปี 2573
หากและอย่างไรวิธีการ JEST จะถูกนำมาใช้โดยผู้เล่นหลักในพื้นที่ AI ยังคงต้องรอดูต่อไป มีรายงานว่า GPT-4o มีค่าใช้จ่าย 100 ล้านดอลลาร์ ในการฝึกอบรม และโมเดลขนาดใหญ่ในอนาคตอาจมีมูลค่าถึงพันล้านดอลลาร์ในเร็วๆ นี้ ดังนั้นบริษัทต่างๆ จึงมีแนวโน้มตามล่าหาหนทางที่จะประหยัดกระเป๋าสตางค์ในแผนกนี้ ผู้หวังดีคิดว่าวิธี JEST จะถูกนำมาใช้เพื่อรักษาอัตราการผลิตการฝึกอบรมในปัจจุบันโดยใช้พลังงานที่ต่ำกว่ามาก ลดต้นทุนของ AI และช่วยเหลือโลก อย่างไรก็ตาม มีความเป็นไปได้มากกว่านั้นมากที่เครื่องจักรแห่งทุนจะเหยียบคันเร่งไว้กับโลหะ โดยใช้วิธี JEST เพื่อรักษาการดึงพลังงานไว้สูงสุดเพื่อการฝึกซ้อมที่รวดเร็วเป็นพิเศษ การประหยัดต้นทุนเทียบกับขนาดผลผลิต ใครจะชนะ?