จะเกิดอะไรขึ้นหาก ChatGPT ได้รับการเทรนนิ่งเกี่ยวกับข่าวและข้อมูลทางการเงิน ที่เก็บข้อมูลมาหลายทศวรรษ BloombergGPT มีเป้าหมายที่จะเป็น AI เฉพาะโดเมนสำหรับข่าวธุรกิจ
ยักษ์ใหญ่ด้านข่าวและข้อมูลได้สร้าง Generative AI ที่มีประสิทธิภาพสูงกว่าคู่แข่ง หากจะมีสำนักข่าวใดจะเป็นบริษัทแรกที่มีโมเดล AI ขนาดมหึมาของตนเอง Bloomberg น่าจะเป็นคำตอบแรกๆ สำหรับความสำเร็จทั้งหมดในช่วงทศวรรษที่ผ่านมา Bloomberg เป็นบริษัทข้อมูลโดยพื้นฐาน ซึ่งมีสมาชิกจำนวนมากสมัครรับบริการเทอร์มินอล มูลค่า $30,000 ต่อปี
If you were going to predict which news company would be the first out with its own massive AI model, Bloomberg would’ve been a good bet. For all its success expanding into consumer-facing news over the past decade, Bloomberg is fundamentally a data company, driven by $30,000/year subscriptions to its terminals.
เตรียมพร้อมเปิดตัว BloombergGPT

วันนี้ Bloomberg ได้เผยแพร่เอกสารการวิจัยที่ให้รายละเอียดเกี่ยวกับการพัฒนา BloombergGPT ซึ่งเป็น large-scale generative artificial intelligence (AI) model แบบจำลองภาษาขนาดใหญ่ (LLM) นี้ได้รับการเทรนนิ่ง โดยดาต้าเซ็ตเฉพาะทางการเงินขนาดใหญ่ รองรับการใช้งานด้วยภาษาธรรมชาติ natural language processing (NLP) ครอบคลุมความต้องการที่หลากหลายในอุตสาหกรรมการเงิน
ความก้าวหน้าล่าสุดในปัญญาประดิษฐ์ (AI) ที่ใช้ LLM ได้แสดงให้เห็นถึงแอปพลิเคชันใหม่ที่น่าตื่นเต้นสำหรับหลาย ๆ โดเมนแล้ว อย่างไรก็ตาม ความซับซ้อนและคำศัพท์เฉพาะของโดเมนทางการเงินรับประกันรูปแบบเฉพาะของโดเมน BloombergGPT แสดงถึงขั้นตอนแรกในการพัฒนาและประยุกต์ใช้เทคโนโลยีใหม่นี้สำหรับอุตสาหกรรมการเงิน โมเดลนี้จะช่วย Bloomberg ในการปรับปรุงงาน NLP ทางการเงินที่มีอยู่ เช่น การวิเคราะห์ความรู้สึก การจดจำชื่อนิติบุคคล การจัดประเภทข่าว และการตอบคำถาม เป็นต้น นอกจากนี้ BloombergGPT จะปลดล็อกโอกาสใหม่สำหรับการรวบรวมข้อมูลจำนวนมหาศาลที่มีอยู่ใน Bloomberg Terminal เพื่อช่วยเหลือลูกค้าของบริษัทได้ดียิ่งขึ้น ในขณะที่นำศักยภาพของ AI มาสู่โดเมนทางการเงิน
รายละเอียดทางเทคนิค เป็นไปตามที่ระบุไว้ในเอกสารการวิจัยนี้ โดย Shijie Wu จาก Bloomberg, Ozan İrsoy, Steven Lu, Vadim Dabravolski, Mark Dredze, Sebastian Gehrmann, Prabhanjan Kambadur, David Rosenberg และ Gideon Mann
ดาต้าเซ็ตของ BloombergGPT ใหญ่แค่ไหน?
บริษัทกล่าวว่า BloombergGPT ได้รับการเทรนนิ่งเกี่ยวกับดาต้าเซ็ตมากกว่า 700 พันล้านโทเค็น ข้อมูลการเทรนนิ่งทั้งหมดมีอะไรบ้าง ในบรรดาโทเค็นกว่า 700 ล้านโทเค็นนั้น 363 พันล้านมาจากข้อมูลทางการเงินของ Bloomberg ซึ่งเป็น ดาต้าเซ็ตเฉพาะโดเมนทางการเงินที่ใหญ่ที่สุด และโทเค็นอีก 345 พันล้านโทเค็นมาจาก “ดาต้าเซ็ตทางการเงินทั่วไป” ที่ได้รับจากที่อื่น
แทนที่จะสร้าง LLM สำหรับวัตถุประสงค์ทั่วไปหรือ LLM ขนาดเล็กสำหรับข้อมูลเฉพาะโดเมนโดยเฉพาะ เราใช้วิธีการแบบผสมผสาน โมเดลทั่วไปครอบคลุมหลายโดเมน สามารถทำงานได้ในระดับสูงในงานที่หลากหลาย และขจัดความต้องการความเชี่ยวชาญพิเศษในช่วงเวลาเทรนนิ่ง อย่างไรก็ตาม ผลลัพธ์จากแบบจำลองเฉพาะโดเมนที่มีอยู่แสดงว่าแบบจำลองทั่วไปไม่สามารถแทนที่ได้ ที่ Bloomberg เราสนับสนุนงานชุดใหญ่และหลากหลาย ซึ่งให้บริการได้ดีในโมเดลทั่วไป แต่แอปพลิเคชันส่วนใหญ่ของเราอยู่ในโดเมนทางการเงิน ซึ่งให้บริการได้ดีกว่าในโมเดลเฉพาะ ด้วยเหตุผลดังกล่าว เราจึงเริ่มสร้างแบบจำลองที่ได้ผลลัพธ์ที่ดีที่สุดในระดับเดียวกันในเกณฑ์มาตรฐานทางการเงิน ในขณะที่ยังคงรักษาประสิทธิภาพการแข่งขันด้วยเกณฑ์มาตรฐาน LLM ทั่วไป
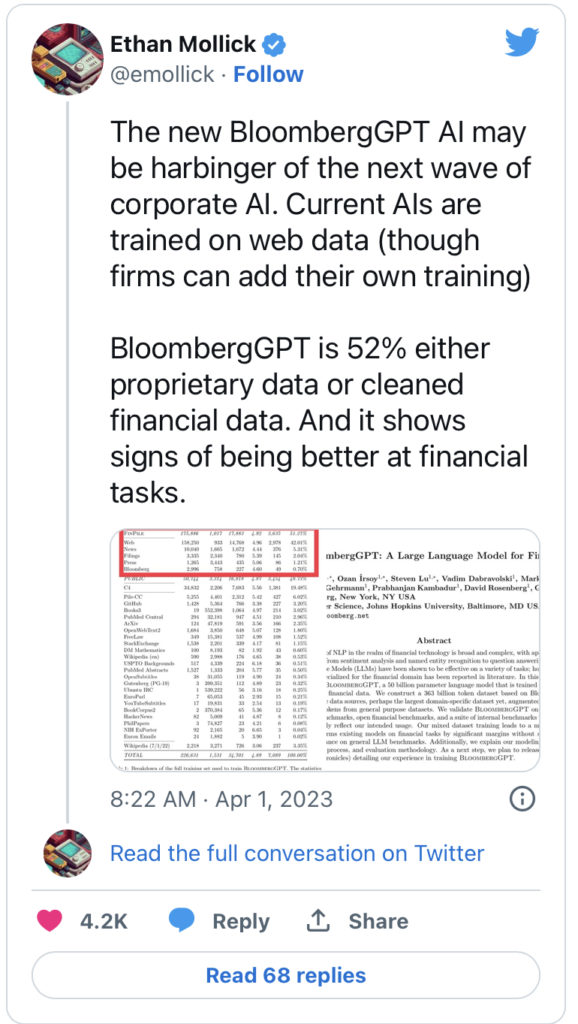
ข้อมูลเฉพาะของบริษัทที่ชื่อว่า FinPile ประกอบด้วย “เอกสารทางการเงินภาษาอังกฤษ ซึ่งประกอบด้วย ข่าว เอกสารข้อมูล ข่าวประชาสัมพันธ์ เอกสารทางการเงินที่ดึงข้อมูลจากเว็บไซต์ และโซเชียลมีเดียที่ดึงมาจากดาต้าเซ็ตของ Bloomberg” ดังนั้น หากคุณเคยอ่านเรื่องราวของ Bloomberg Businessweek ในช่วงไม่กี่ปีที่ผ่านมา เช่นเดียวกับเอกสารที่ยื่นต่อ ก.ล.ต. การถอดเสียงทางทีวีของ Bloomberg และ “ข้อมูลอื่นๆ ที่เกี่ยวข้องกับตลาดการเงิน” นอกจากนี้ยังได้รับการเทรนนิ่งดาต้าเซ็ตสำนักข่าวที่ไม่ใช่ของ Bloomberg ด้วย
หมวดหมู่ข่าวประกอบด้วยแหล่งข่าวทั้งหมด ยกเว้นบทความข่าวที่เขียนโดยนักข่าวของ Bloomberg โดยรวมแล้ว มีแหล่งข่าวภาษาอังกฤษหลายร้อยรายการใน FinPile… โดยทั่วไป เนื้อหาในดาต้าเซ็ตนี้มาจากแหล่งข่าวที่มีชื่อเสียงซึ่งเกี่ยวข้องกับชุมชนการเงินเพื่อความถูกต้องของข้อมูล ข้อเท็จจริงที่รอบด้าน และลดอคติ
ข้อมูลที่ไม่เฉพาะเจาะจงทางการเงินรวมถึงดาต้าเซ็ตขนาดใหญ่ที่รู้จักกันในชื่อ The Pile รวมทุกอย่างตั้งแต่คำบรรยายใน YouTube ไปจนถึง Project Gutenberg ไปจนถึงข้อมูลจากอีเมล ในการเทรนนิ่ง AI
BloombergGPT ทำอะไรได้บ้าง?
เนื่องจากแชร์ดาต้าเซ็ตเทรนนิ่งกับ LLM อื่นๆ BloombergGPT จึงสามารถรองรับการใช้งาน เช่นเดียวกับ ChatGPT และโมเดลที่คล้ายกันได้ และยังตรงความต้องการของผู้ใช้ Bloomberg มากกว่า สามารถแปลภาษาธรรมชาติทางการเงิน (“apple and ibm market cap and eps”) เป็น Bloomberg Query Language ที่ผู้ใช้เทอร์มินอลของ Bloomberg ใช้งานอยู่
(get(cur_mkt_cap,is_eps) for([’AAPL US Equity’,’IBM US Equity’]))
นอกจากนี้ยังสามารถแนะนำหัวข้อข่าวสไตล์ Bloomberg สำหรับเขียนเนื้อหาข่าว
อินพุต: ตลาดที่อยู่อาศัยของสหรัฐมีมูลค่าลดลง 2.3 ล้านล้านดอลลาร์หรือ 4.9% ในช่วงครึ่งหลังของปี 2565 ตามข้อมูลของ Redfin นั่นคือการลดลงในแง่เปอร์เซ็นต์ที่ใหญ่ที่สุดนับตั้งแต่วิกฤตที่อยู่อาศัยในปี 2551 เมื่อมูลค่าลดลง 5.8% ในช่วงเวลาเดียวกัน
เอาท์พุต: ราคาบ้านลดลงมากที่สุดในรอบ 15 ปี
อินพุต: เศรษฐกิจโลกในวันนี้อยู่ในจุดที่ดีขึ้นกว่าหลายเดือนที่ผ่านมาที่คาดการณ์ไว้ เจเน็ต เยลเลนกล่าวที่ G20 ที่บ้าน เธอชี้ไปที่เศรษฐกิจสหรัฐที่ฟื้นตัวได้ ซึ่งอัตราเงินเฟ้อทั่วไปได้ลดลงและตลาดแรงงานมีความแข็งแกร่ง นอกจากนี้ เธอยังเรียกร้องให้ไอเอ็มเอฟดำเนินการอย่างรวดเร็วเพื่อไปสู่โครงการที่สนับสนุนทางการเงินอย่างเต็มที่สำหรับยูเครน
เอาท์พุต: เยลเลนมองว่าเศรษฐกิจโลกฟื้นตัวได้ดีเกินคาด
อินพุต: Google ถูกฟ้องโดยสหรัฐฯ และแปดรัฐที่พยายามยุติธุรกิจเทคโนโลยีโฆษณา เนื่องจากถูกกล่าวหาว่าผูกขาดตลาดโฆษณาดิจิทัล คดีนี้เป็นความท้าทายครั้งใหญ่ครั้งแรกของฝ่ายบริหารของ Biden ต่อยักษ์ใหญ่ด้านเทคโนโลยี และเป็นหนึ่งในช่วงเวลาที่หายากนับตั้งแต่ปี 1982 ที่ DOJ พยายามแยกบริษัทยักษ์ใหญ่ออกจากกัน
เอาท์พุต: Google ฟ้องในข้อหาผูกขาดในตลาดโฆษณาออนไลน์
พวกเขากล่าวว่ม มีการปรับแต่งให้ดีขึ้น เพื่อตอบคำถามที่เกี่ยวข้องกับธุรกิจโดยเฉพาะ ไม่ว่าจะเป็นการวิเคราะห์ความรู้สึก การจัดหมวดหมู่ การดึงข้อมูล หรืออย่างอื่นทั้งหมด (เช่น ถ้าระบุตัว CEO ของบริษัทที่สนใจ ใน prompt อย่างชัดเจน แชตบอตจะทำงานได้ดีขึ้น”)
เอกสารฉบับนี้ประกอบด้วยชุดการเปรียบเทียบประสิทธิภาพกับ GPT-3 และ LLM อื่นๆ และพบว่า BloombergGPT มีความโดดเด่นในเรื่องงานทั่วไป อย่างน้อยก็เมื่อต้องเผชิญหน้ากับโมเดลที่มีขนาดใกล้เคียงกัน และมีประสิทธิภาพดีกว่าโมเดลเฉพาะทางด้านการเงินจำนวนมาก (The internal testing battery includes such carnival-game-ready terms as “Penguins in a Table,” “Snarks,” “Web of Lies,” and the dreaded “Hyperbaton.”)
จากงานหลายสิบงานในเกณฑ์มาตรฐานมากมาย ภาพที่ชัดเจนจะปรากฏขึ้น ในบรรดาโมเดลที่มีพารามิเตอร์นับหมื่นล้านที่เราเปรียบเทียบกัน BloombergGPT ทำงานได้ดีที่สุด นอกจากนี้ ในบางกรณี มันสามารถแข่งขันหรือมีประสิทธิภาพเหนือกว่าโมเดลที่ใหญ่กว่ามาก (พารามิเตอร์นับแสนล้าน) แม้ว่าเป้าหมายของเราสำหรับ BloombergGPT คือการเป็นโมเดลที่ดีที่สุดในระดับเดียวกันสำหรับงานทางการเงิน และเราได้รวมข้อมูลการเทรนนิ่งสำหรับวัตถุประสงค์ทั่วไปเพื่อสนับสนุนการเทรนนิ่งเฉพาะโดเมน แต่โมเดลยังคงได้รับความสามารถสำหรับข้อมูลสำหรับวัตถุประสงค์ทั่วไปที่เกินโมเดลที่มีขนาดใกล้เคียงกัน และในบางกรณีตรงกันหรือมีประสิทธิภาพดีกว่ารุ่นที่ใหญ่กว่ามาก
นอกเหนือจาก Penguins แล้ว ไม่ใช่เรื่องยากที่จะจินตนาการถึงกรณีการใช้งานเฉพาะเจาะจงที่นอกเหนือไปจากการเปรียบเทียบ ไม่ว่าจะเป็นสำหรับนักข่าวของ Bloomberg หรือลูกค้าเทอร์มินัล (การประกาศของบริษัทไม่ได้ระบุว่ามีแผนจะทำอะไรกับสิ่งที่บริษัทสร้างขึ้น) ดาต้าเซ็ต ~ทั้งหมดของการรายงานธุรกิจภาษาอังกฤษระดับพรีเมียมของโลก — รวมถึงข้อมูลทางการเงินที่มีโครงสร้างและอื่น ๆ ที่สนับสนุน — เป็นเพียงส่วนหนึ่งของดาต้าเซ็ตจำนวนมากที่ Generative AI ได้รับการเทรนนิ่ง สำหรับ LLM เป็นไปได้ที่ BloombergGPT อาจให้คำตอบแบบมั่วๆ hallucinate ขึ้นกับดาต้าเซ็ตที่ใช้เทรนนิ่ง ส่ามีความคลาดเคลื่อน potential biases มากน้อยเพียงใด
BloombergGPT เป็นแรงบันดาลใจให้กับสำนักข่าวอื่น ๆ ได้ Bloomberg มีความพร้อม ด้วยดาต้าเซ็ตขนาดใหญ่ ข้อมูลที่รวบรวมและผลิตภัณฑ์ที่สามารถนำไปใช้ได้ แต่เชื่อว่ามีอนาคต Generative AI จะถูกใช้ กับสำนักข่าวทุกระดับ โดยเฉพาะ ผู้ที่มีไฟล์เก็บถาวรดิจิทัลขนาดใหญ่ ลองนึกภาพว่า Anytown Gazette เทรนนิ่ง AI ด้วยดาต้าเซ็ต คลังเอกสารหนังสือพิมพ์อายุ 100 ปี รวมถึงเอกสารเมือง/เทศมณฑล/รัฐชุดใหญ่ และแหล่งข้อมูลท้องถิ่นอื่นๆ ใดก็ตามที่สามารถเข้าถึงได้ แน่นอนว่าเป็นสเกลที่แตกต่างอย่างสิ้นเชิงกว่าที่ Bloomberg สามารถเข้าถึงได้ และอาจมีประโยชน์ในฐานะเครื่องมือภายในมากกว่าสิ่งที่เปิดเผยต่อสาธารณะ แต่ด้วยความก้าวหน้าที่เหลือเชื่อของ AI ในปีที่ผ่านมา มันอาจเป็นแนวคิดที่ถูกนำมาใช้อย่างแพร่หลายกว่าที่คุณคิด