เอกสารงานวิจัย AI นี้ แนะนำหัวข้อ SELF-REFINE: เฟรมเวิร์กสำหรับการปรับปรุงผลลัพธ์เริ่มต้นจาก LLM ผ่าน Iterative Feedback และ Refinement
This AI Paper Introduces SELF-REFINE: A Framework For Improving Initial Outputs From LLMs Through Iterative Feedback And Refinement

SELF-REFINE: A Framework For Improving Initial Outputs From LLMs
Iterative Feedback เป็นลักษณะสำคัญของการแก้ปัญหาของมนุษย์ การ Iterative Feedback เป็นกระบวนการที่เกี่ยวข้องกับการสร้างแบบร่างเริ่มต้นและจากนั้นปรับปรุงผ่านการแสดงความคิดเห็นด้วยตนเอง ตัวอย่างเช่น ในขณะที่เขียนอีเมลถึงเพื่อนร่วมงานเพื่อขอเอกสาร บุคคลนั้นจะใช้คำขอที่ตรงไปตรงมาก่อน เช่น “ให้ข้อมูลทันที” แต่หลังจากคิดอยู่ครู่หนึ่ง ผู้เขียนก็ตระหนักได้ว่าวลีนี้อาจถูกพิจารณาว่าไม่เป็นมิตรและเปลี่ยนเป็น “คุณช่วยกรุณาให้ข้อมูลแก่ฉันได้ไหม” การใช้ข้อเสนอแนะและการปรับเปลี่ยนซ้ำๆ ในการศึกษาครั้งนี้แสดงให้เห็นว่าโมเดลภาษาขนาดใหญ่ (LLM) สามารถเลียนแบบกระบวนการรับรู้นี้ในมนุษย์ได้สำเร็จ
แม้ว่า LLMs จะสามารถสร้างผลลัพธ์ที่สอดคล้องกันในระยะเริ่มต้น แต่มักจะขาดประสิทธิภาพเมื่อต้องจัดการกับความต้องการที่ซับซ้อนมากขึ้น โดยเฉพาะอย่างยิ่งสำหรับงานที่มีวัตถุประสงค์หลายอย่าง (เช่น การสร้างคำตอบในบทสนทนาที่มีเกณฑ์ เช่น การทำให้คำตอบมีความเกี่ยวข้อง มีส่วนร่วม และปลอดภัย) หรือสิ่งเหล่านั้น มีเป้าหมายที่ชัดเจนน้อยกว่า (เช่น เพิ่มความสามารถในการอ่านโปรแกรม) LLM สมัยใหม่อาจสร้างผลลัพธ์ที่เข้าใจได้ในกรณีดังกล่าว ยังคงต้องมีการปรับปรุงซ้ำเพื่อรับประกันว่าข้อกำหนดการมอบหมายทั้งหมดได้รับการแก้ไขและบรรลุระดับคุณภาพที่เหมาะสม
วิธีการขั้นสูงที่อาศัยแบบจำลองการให้รางวัลและการกำกับดูแลจากบุคคลที่สามเรียกข้อมูลการฝึกอบรมจำนวนมหาศาลหรือคำอธิบายประกอบของมนุษย์ที่มีราคาแพง ซึ่งมักนำไปใช้ได้จริง ข้อเสียเหล่านี้เน้นย้ำถึงความจำเป็นในวิธีการสร้างข้อความที่ปรับเปลี่ยนได้และมีประสิทธิภาพมากขึ้น ซึ่งอาจใช้กับงานหลายอย่างโดยมีการตรวจสอบเพียงเล็กน้อย ในการศึกษานี้ นักวิจัยจาก CMU, Allen Institute, University of Washington, NVIDIA, UCSD และ Google Research เสนอให้ SELF-REFINE เอาชนะข้อจำกัดเหล่านี้และจำลองกระบวนการผลิตที่สร้างสรรค์ของมนุษย์ได้ดียิ่งขึ้นโดยไม่ต้องมีวงจรป้อนกลับที่มีค่าใช้จ่ายสูง (รูปที่ 1).
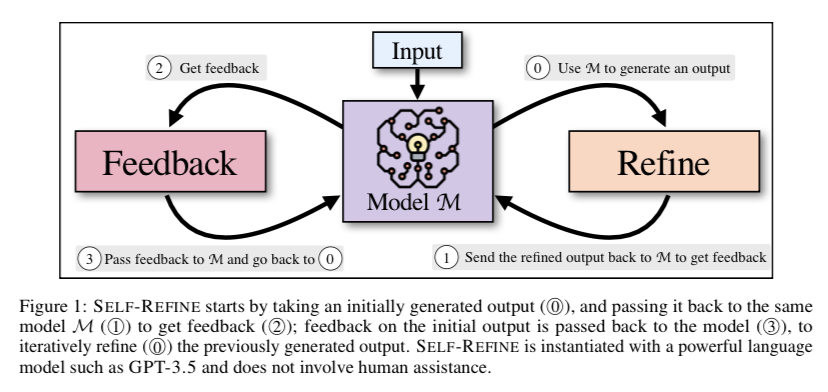
รูปที่ 1: SELF-REFINE เริ่มต้นด้วยการรับเอาต์พุต (O) ที่สร้างขึ้นในขั้นต้น และส่งกลับไปยังรุ่น M (O) เดิมเพื่อรับคำติชม (); ข้อเสนอแนะเกี่ยวกับเอาต์พุตเริ่มต้นจะถูกส่งกลับไปยังโมเดล (3) เพื่อ Iterative Feedback (O) เอาต์พุตที่สร้างไว้ก่อนหน้านี้ SELF-REFINE ได้รับการยกตัวอย่างด้วยภาษาที่ทรงพลัง
รุ่นเช่น GPT-3.5 และไม่เกี่ยวข้องกับความช่วยเหลือของมนุษย์
ทั้งสองส่วนของ SELF-REFINE—FEEDBACK และ REFINE—ทำงานร่วมกันเป็นวงจรวนซ้ำเพื่อให้ได้ผลลัพธ์คุณภาพสูง พวกเขาส่งรุ่น M (1) เดียวกันซึ่งเป็นเอาต์พุตแบบร่างเริ่มต้นที่ผลิตโดยรุ่น M (0) เพื่อรับข้อเสนอแนะ (1) โมเดลเดียวกัน (3) ได้รับข้อเสนอแนะเกี่ยวกับการผลิตดั้งเดิม ซึ่งปรับปรุง (0) เอาต์พุตที่ผลิตในขั้นต้นซ้ำแล้วซ้ำอีก ทำซ้ำขั้นตอนนี้ไปเรื่อย ๆ จนกว่าแบบจำลองจะพิจารณาว่าไม่จำเป็นต้องปรับปรุงเพิ่มเติม ซึ่งจุดนั้นกระบวนการจะสิ้นสุดลง วิทยานิพนธ์หลักของการศึกษานี้คือในสถานการณ์ไม่กี่ช็อต แบบจำลองภาษาพื้นฐานเดียวกันจะจัดการกับคำติชมและ Refinement
SELF-REFINE นำเสนอกลยุทธ์การทำซ้ำครั้งแรก เพื่อปรับปรุงการสร้างโดยใช้ข้อเสนอแนะ NL อย่างมีประสิทธิภาพ
รูปที่ 1 แสดงขั้นตอนในตัวอย่าง พวกเขาใช้ SELF-REFINE เพื่อทำงานต่างๆ ที่ครอบคลุมหลายขอบเขต และต้องการคำติชมและเทคนิคการแก้ไข เช่น การเขียนรีวิวใหม่ การสร้างตัวย่อ การสร้างแบบจำกัด การสร้างเรื่องเล่า การเขียนโค้ดใหม่ การสร้างการตอบสนอง และการกำจัดพิษ ส่วนประกอบหลักของพวกเขาได้รับการสร้างอินสแตนซ์โดยใช้กลยุทธ์การกระตุ้นเตือนเพียงไม่กี่ช็อต ซึ่งช่วยให้เราสามารถใช้อินสแตนซ์สองสามตัวอย่างเพื่อเริ่มต้นการเรียนรู้ของโมเดลอย่างรวดเร็ว วิธีการทำซ้ำของพวกเขา ซึ่งรวมถึงการทดลอง การวิเคราะห์องค์ประกอบ งานที่หลากหลาย การสร้างข้อเสนอแนะที่เป็นประโยชน์ และเกณฑ์การหยุด มีวัตถุประสงค์เพื่อเป็นแนวทางในการวิจัยในอนาคตในสาขานี้
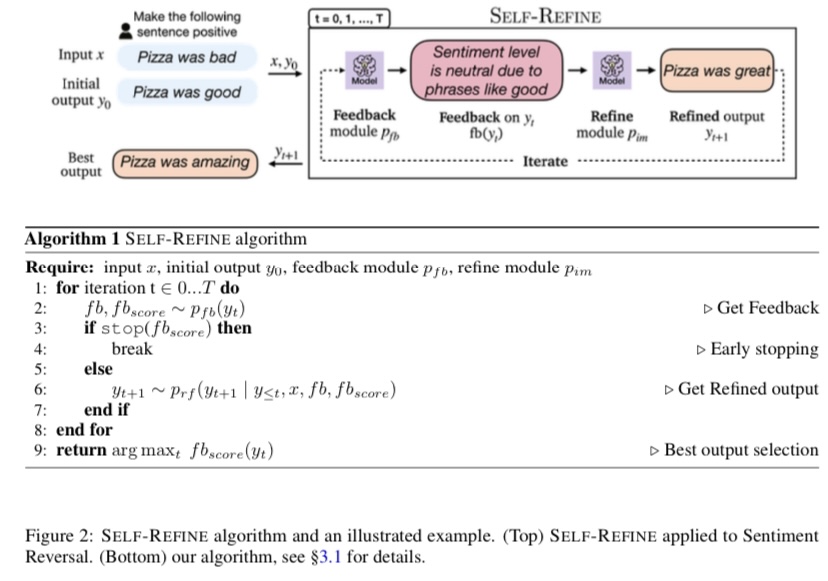
รูปที่ 2: อัลกอริทึม SELF-REFINE และตัวอย่างที่แสดง (บนสุด) SELF-REFINE นำไปใช้กับการกลับรายการความรู้สึก (ด้านล่าง) อัลกอริทึมของเรา
สรุปผลงานของพวกเขาคือ:
เพื่อช่วยให้ LLM ทำงานได้ดีขึ้นในงานที่หลากหลาย พวกเขาแนะนำ SELF-REFINE ซึ่งเป็นเทคนิคเฉพาะที่ช่วยให้พวกเขาปรับปรุงผลลัพธ์โดยใช้ความคิดเห็นซ้ำๆ วิธีการของพวกเขาต้องการ LLM เดียวซึ่งแตกต่างจากความพยายามก่อนหน้านี้ซึ่งใช้การเรียนรู้แบบเสริมแรงหรือข้อมูลการฝึกอบรมภายใต้การดูแล
พวกเขาทำการทดลองอย่างกว้างขวางในเจ็ดงานที่แตกต่างกัน ได้แก่ ตรวจสอบการเขียนซ้ำ การสร้างตัวย่อ การสร้างเรื่องราว การเขียนโค้ดใหม่ การสร้างการตอบสนอง การสร้างเงื่อนไข และการกำจัดผลลัพธ์ที่ไม่เหมาะสม และแสดงให้เห็นว่า SELF-REFINE ทำงานได้ดีขึ้นอย่างน้อย 5% และบางครั้งอาจมากกว่านั้น ดีกว่า Generate AI ต้นแบบ ที่มีชื่อเสียงอย่าง GPT-3.5 และแม้แต่ GPT-4 ถึง 40%