An End-To-End RLHF Pipeline To Train ChatGPT-like Models

ไม่ได้เป็นการกล่าวเกินจริง ที่ว่า ChatGPT และแชทบอตแนวคิดที่คล้ายกัน มีผลในการปฏิวัติโลกดิจิทัล ด้วยเหตุผลนี้ ชุมชนโอเพ่นซอร์ส AI กำลังทำงานในโครงการบางโครงการ (เช่น ChatLLaMa, Alpaca เป็นต้น) ซึ่งมีจุดมุ่งหมายเพื่อให้โมเดลรูปแบบ ChatGPT พร้อมใช้งานอย่างกว้างขวางมากขึ้น โมเดลเหล่านี้มีความยืดหยุ่นอย่างมากและสามารถดำเนินการต่างๆ เช่น การสรุป การเขียนโค้ด และการแปลในระดับที่มนุษย์เชี่ยวชาญหรือเหนือกว่าได้
แม้จะมีความพยายามที่น่าประทับใจเหล่านี้ แต่ไปป์ไลน์ RLHF แบบ end-to-end ที่เปิดเผยต่อสาธารณะก็ยังไม่สามารถฝึกโมเดลที่เหมือน ChatGPT ที่แข็งแกร่งได้ ประสิทธิภาพการฝึกอบรมมักจะน้อยกว่า 5% ของความสามารถของเครื่องเหล่านี้ แม้ว่าจะมีการเข้าถึงทรัพยากรการประมวลผลดังกล่าวก็ตาม แม้จะเข้าถึงคลัสเตอร์แบบ multi-GPU ได้ แต่ระบบที่มีอยู่ก็ไม่สามารถรองรับการฝึกอบรม ChatGPT รุ่นใหม่ล่าสุดที่ง่าย รวดเร็ว และราคาไม่แพงด้วยพารามิเตอร์หลายพันล้านพารามิเตอร์ได้
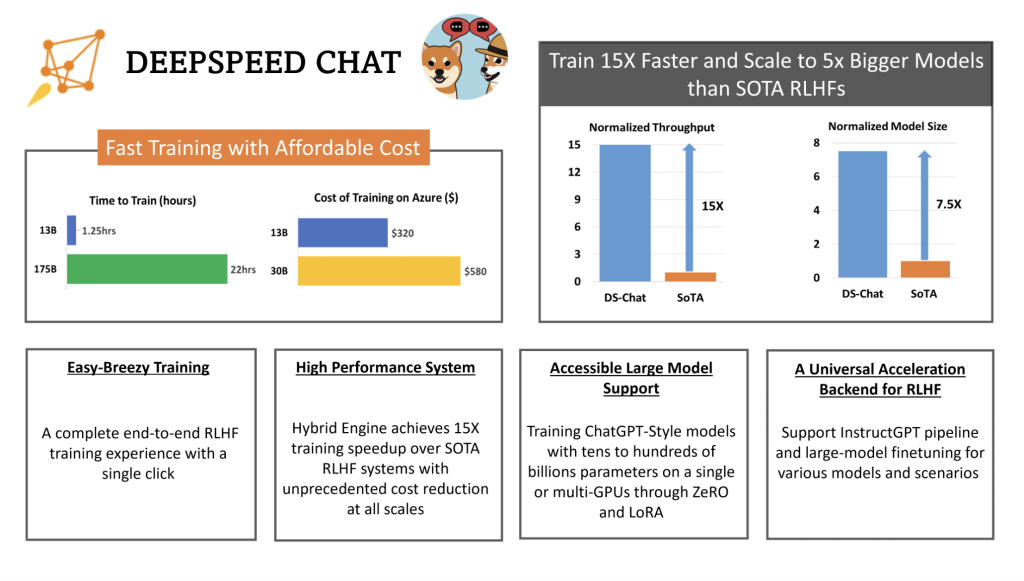
ข้อจำกัดเหล่านี้เกิดจากข้อเท็จจริงที่ว่าไปป์ไลน์การฝึกอบรม RLHF ที่ซับซ้อนซึ่งใช้โดย InstructGPT ไม่ได้รับการสนับสนุนอย่างดีจากระบบ DL ที่มีอยู่ ซึ่งได้รับการปรับให้เหมาะสมสำหรับไปป์ไลน์ก่อนการฝึกอบรมและการปรับแต่งแบบละเอียด เพื่อให้โมเดลที่เหมือน ChatGPT ใช้งานได้อย่างกว้างขวางมากขึ้นและเข้าถึงการฝึกอบรม RLHF ได้ง่ายขึ้น ทีมงาน Microsoft จึงเปิดตัว DeepSpeed-Chat ซึ่งนำเสนอไปป์ไลน์ RLHF แบบ end-to-end เพื่อฝึกโมเดลที่เหมือน ChatGPT มันมีคุณสมบัติดังต่อไปนี้:
- A Convenient Environment for Training and Inferring ChatGPT-Similar Models: สภาพแวดล้อมที่สะดวกสำหรับการฝึกอบรมและการอนุมาน ChatGPT-Similar Models: การฝึก InstructGPT สามารถทำได้บนโมเดล Huggingface ที่ฝึกไว้ล่วงหน้าด้วยสคริปต์เดียวที่ใช้ระบบ DeepSpeed-RLHF ซึ่งช่วยให้ผู้ใช้สร้างโมเดลที่เหมือน ChatGPT ได้ หลังจากฝึกแบบจำลองแล้ว สามารถใช้ API การอนุมานเพื่อทดสอบการโต้ตอบการสนทนาได้
- The DeepSpeed-RLHF Pipeline: ไปป์ไลน์ DeepSpeed-RLHF: ไปป์ไลน์ DeepSpeed-RLHF จำลองไปป์ไลน์การฝึกอบรมจากเอกสาร InstructGPT เป็นส่วนใหญ่ ทีมงานมั่นใจว่าสอดคล้องกันอย่างสมบูรณ์และแน่นอนระหว่างสามขั้นตอน ก) การปรับแต่งแบบละเอียดภายใต้การดูแล (SFT) ข) การปรับแต่งโมเดลรางวัลแบบละเอียด และค) การเรียนรู้แบบเสริมแรงด้วยคำติชมจากมนุษย์ (RLHF) นอกจากนี้ พวกเขายังมีเครื่องมือสำหรับการแยกและผสมข้อมูลที่ทำให้สามารถฝึกโดยใช้ข้อมูลจากแหล่งต่างๆ
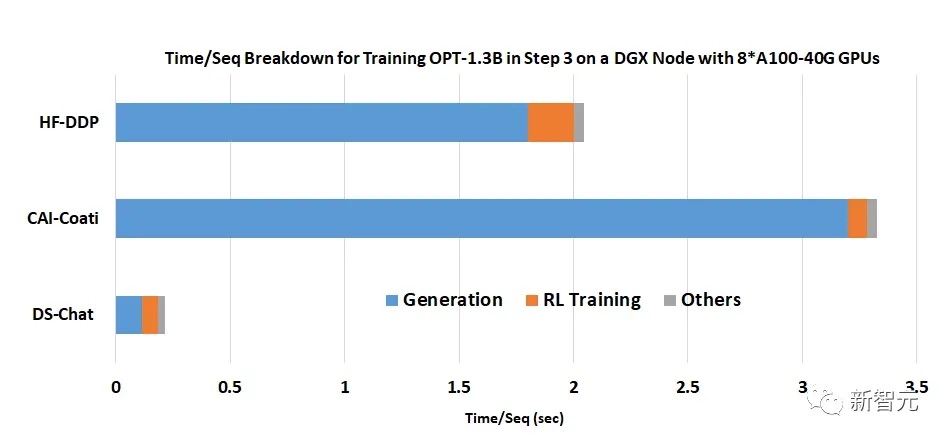
- The DeepSpeed-RLHF System:ระบบ DeepSpeed-RLHF: Hybrid Engine (DeepSpeed-HE) สำหรับ RLHF เป็นระบบที่ทรงพลังและซับซ้อนที่รวมความสามารถในการฝึกอบรมและการอนุมานของ DeepSpeed เข้าไว้ด้วยกัน Hybrid Engine สามารถสลับไปมาระหว่างโหมดการอนุมานและโหมดการฝึกของ RLHF ได้อย่างง่ายดาย โดยใช้ประโยชน์จากการปรับให้เหมาะสมของ DeepSpeed-Inference เช่น tensor-parallelism และเคอร์เนลหม้อแปลงประสิทธิภาพสูงสำหรับรุ่น รวมถึงกลยุทธ์การปรับหน่วยความจำที่เหมาะสมมากมายของ RLHF เช่น ZeRO และ LoRA เพื่อเพิ่มประสิทธิภาพการจัดการหน่วยความจำและการถ่ายโอนข้อมูลในขั้นตอนต่างๆ ของ RLHF ให้ดียิ่งขึ้น DeepSpeed-HE ยังรับรู้เพิ่มเติมเกี่ยวกับไปป์ไลน์ RLHF ทั้งหมด ระบบ DeepSpeed-RLHF บรรลุประสิทธิภาพในระดับที่ไม่เคยมีมาก่อน ทำให้ชุมชน AI สามารถเข้าถึงการฝึกอบรมเกี่ยวกับโมเดล RLHF ที่ซับซ้อนได้อย่างรวดเร็ว ราคาถูก และสะดวก
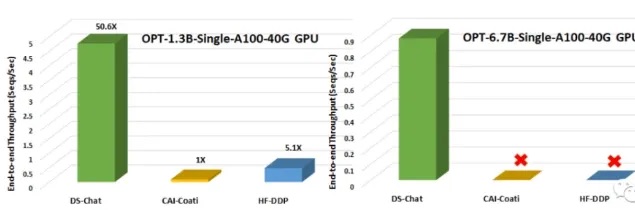
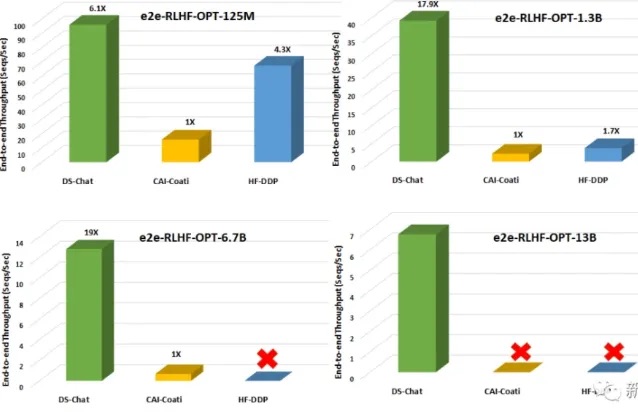
- Efficiency and Affordability:ประสิทธิภาพและความสามารถในการจ่าย: เนื่องจาก DeepSpeed-HE เร็วกว่าระบบทั่วไปถึง 15 เท่า การฝึกอบรม RLHF จึงอาจเสร็จสิ้นได้อย่างรวดเร็วและราคาถูก
- Excellent Scalability: ความสามารถในการปรับขนาดที่ยอดเยี่ยม: ความสามารถในการปรับขนาดที่แข็งแกร่งของ DeepSpeed-HE บนระบบ multi-node multi-GPU ช่วยให้สามารถรองรับโมเดลที่มีพารามิเตอร์หลายแสนล้านตัว
- Expanding Access to RLHF Education: ขยายการเข้าถึงการศึกษา RLHF: DeepSpeed-HE ช่วยให้นักวิทยาศาสตร์ข้อมูลไม่ต้องเข้าถึงระบบหลาย GPU เพื่อสร้างโมเดล RLHF ที่ไม่เพียงแค่ของเล่นเท่านั้น แต่ยังมีขนาดใหญ่และทรงพลังที่สามารถนำไปใช้ในสภาพแวดล้อมจริงได้ด้วย GPU เพียงตัวเดียวสำหรับการฝึกอบรม
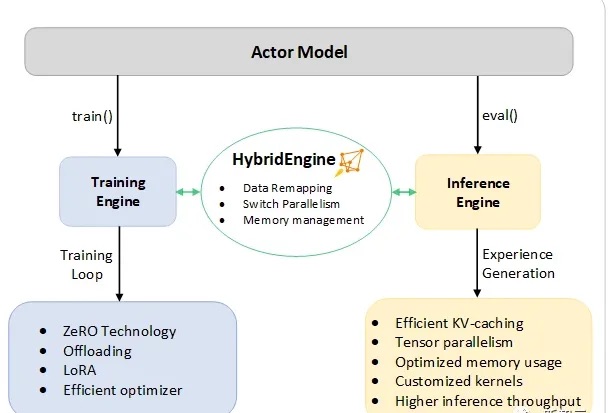
นักวิจัยได้รวมไปป์ไลน์การฝึกอบรมแบบ end-to-end ทั้งหมดใน DeepSpeed-Chat และจำลองตาม InstructGPT เพื่อทำให้กระบวนการฝึกอบรมมีความคล่องตัวมากที่สุดเท่าที่จะเป็นไปได้
กระบวนการผลิต ประกอบด้วย 3 ขั้นตอน:
- โมเดลพรีเทรน: pretrained language model ได้รับการปรับอย่างละเอียด ( fine-tuned) ผ่าน supervised fine-tuning (SFT) ซึ่งจะมีการเลือกคำถามอย่างระมัดระวังให้มนุษย์ทำการพรีเทรน
- ขั้นตอนไป ทีมงานดำเนินการ “reward model fine-tuning” ซึ่งเกี่ยวข้องกับการฝึกอบรมโมเดล different Reward model (RW) ที่เล็กกว่า SFT โดยใช้ดาต้าเซ็ตที่ประกอบด้วยคำตอบซึ่งได้รับการจัดอันดับโดยมนุษย์ ในคำถามเดียวกัน
- ขั้นตอนสุดท้าย ในการฝึกอบรม RLHF อัลกอริทึม Proximal Policy Optimization (PPO) ใช้เพื่อปรับโมเดล SFT เพิ่มเติมด้วยผลตอบรับรางวัลจากโมเดล RW
ชุมชน AI สามารถเข้าถึง DeepSpeed-Chat ได้แล้ว ด้วยธรรมชาติแบบโอเพ่นซอร์ส บนเว็บไซต์ DeepSpeed GitHub

รายงานโดย Tanushree Shenwai : Tanushree Shenwai เป็นที่ปรึกษาฝึกงานที่ MarktechPost ปัจจุบันเธอกำลังศึกษาต่อด้าน B.Tech จากสถาบันเทคโนโลยีแห่งอินเดีย (IIT), Bhubaneswar เธอเป็นผู้ที่คลั่งไคล้วิทยาศาสตร์ข้อมูลและมีความสนใจอย่างมากในขอบข่ายของการประยุกต์ใช้ปัญญาประดิษฐ์ในด้านต่างๆ เธอหลงใหลในการสำรวจความก้าวหน้าใหม่ๆ ของเทคโนโลยีและการประยุกต์ใช้ในชีวิตจริง