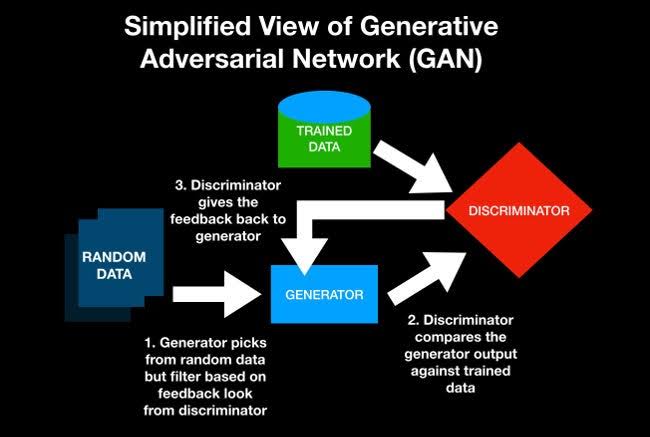
Generative Adversarial Networks หรือเรียกสั้นๆ ว่า GAN เป็นแนวทางในการสร้าง Generative Model โดยใช้วิธี Deep learning methods เช่น Convolutional Neural Networks (CNN) GAN เป็น Machine Learning แบบสร้างเลิร์นนิ่งทาสก์โดยไม่ใช้ supervisor ที่เกี่ยวข้องกับการค้นหาและเรียนรู้ความสม่ำเสมอหรือรูปแบบในข้อมูลอินพุตโดยอัตโนมัติในลักษณะที่โมเดลสามารถนำไปใช้สร้างหรือแสดงตัวอย่างใหม่ที่น่าจะดึงมาจากชุดข้อมูลดั้งเดิม
Generative Adversarial Networks, or GANs for short, are an approach to generative modeling using deep learning methods, such as convolutional neural networks. Generative modeling is an unsupervised learning task in machine learning that involves automatically discovering and learning the regularities or patterns in input data in such a way that the model can be used to generate or output new examples that plausibly could have been drawn from the original dataset. GANs are a clever way of training a generative model by framing the problem as a supervised learning problem with two sub-models: the generator model that we train to generate new examples, and the discriminator model that tries to classify examples as either real (from the domain) or fake (generated). The two models are trained together in a zero-sum game, adversarial, until the discriminator model is fooled about half the time, meaning the generator model is generating plausible examples. GANs are an exciting and rapidly changing field, delivering on the promise of generative models in their ability to generate realistic examples across a range of problem domains, most notably in image-to-image translation tasks such as translating photos of summer to winter or day to night, and in generating photorealistic photos of objects, scenes, and people that even humans cannot tell are fake.
Generative Adversarial Networks
Generative Adversarial Networks (GAN) เป็นวิธีที่ชาญฉลาดในการฝึก Generative model โดยการกำหนดกรอบปัญหาว่าเป็นปัญหาการเรียนรู้แบบมีผู้สอนโดยมีแบบจำลองย่อยสองแบบ: โมเดลตัวกำเนิดที่เราฝึกเพื่อสร้างตัวอย่างใหม่ และแบบจำลองตัวจำแนกที่พยายามจำแนกตัวอย่างว่าเป็นของจริง (จาก โดเมน) หรือปลอม (สร้างขึ้น) แบบจำลองทั้งสองได้รับการฝึกฝนร่วมกันในเกมผลรวมศูนย์ ซึ่งเป็นคู่ต่อสู้กัน จนกว่าแบบจำลองผู้เลือกปฏิบัติจะถูกหลอกประมาณครึ่งเวลา หมายความว่า Generative Model กำลังสร้างตัวอย่างที่น่าเชื่อถือ GAN เป็นสาขาที่น่าตื่นเต้นและเปลี่ยนแปลงอย่างรวดเร็ว โดยส่งมอบตามคำมั่นสัญญาของแบบจำลองเชิงกำเนิดในความสามารถของพวกเขาในการสร้าง