รู้จัก BERT และผองเพื่อน เหล่า Encoder ซึ่งทำหน้าที่เปลี่ยนข้อมูลให้เป็นเวกเตอร์คณิตศาสตร์ของ Transformer เป็นเทคนิคการประมวลผลของโครงสร้างเครือข่าย (NLP) มีบทบาทในการช่วย Google ให้เข้าใจและแสดงผลการค้นหาที่ตรงกับ Keywords นั้นๆ มากที่สุด ปัจจุบัน มีหลายบริษัทที่พัฒนาโมเดลเอ็นโค้ดเดอร์จาก Transformers ต่อยอดจาก BERT (Bidirectional Encoder Representations from Transformers) ให้เหมาะสมกับการใช้งานที่หลากหลาย BERT เป็นโมเดลภาษาแบบ pre-trained ซึ่งใช้งานอย่างแพร่หลายสำหรับงานประมวลผลภาษาธรรมชาติ (NLP) เช่น การจัดประเภทข้อความ การตอบคำถาม และ Named Entity Recognition หรือ NER คือ การสกัดชื่อเฉพาะในประโยค
ตัวอย่างบางส่วนของบริษัทที่พัฒนาโมเดล encoder โดยใช้ BERT:
- Hugging Face: Hugging Face เป็นบริษัทที่พัฒนาไลบรารีและเครื่องมือ NLP แบบโอเพ่นซอร์ส พวกเขาได้พัฒนาหลายรุ่นตาม BERT รวมถึง DistilBERT, RoBERTa และ GPT-2
- Google: Google เป็นผู้พัฒนาดั้งเดิมของ BERT และพวกเขายังคงทำงานเพื่อปรับปรุงโมเดลต่อไป พวกเขายังได้พัฒนารุ่นอื่นๆ ตาม BERT เช่น ALBERT และ ELECTRA
- OpenAI: OpenAI เป็นองค์กรวิจัยที่พัฒนาโมเดลที่ใช้ Transformer หลายรุ่น รวมถึง GPT-3 ซึ่งอิงตามสถาปัตยกรรม Transformer ที่ใช้ใน BERT
- Microsoft: Microsoft ได้พัฒนาหลายรุ่นตาม BERT รวมถึง MT-DNN (Multi-Task Deep Neural Network) และ UniLM (Unified Language Model)
- Facebook: Facebook ได้พัฒนาโมเดลต่างๆ ตาม BERT รวมถึง XLM (Cross-lingual Language Model) และ RoBERTa
บริษัทเหล่านี้และบริษัทอื่นๆ กำลังพัฒนาโมเดล encoder ที่ใช้ Transformers และ BERT เพื่อปรับปรุงงาน NLP

There are many companies developing encoder models based on Transformers, which extend BERT (Bidirectional Encoder Representations from Transformers) for various applications. BERT is a pre-trained language model that is widely used for natural language processing (NLP) tasks, such as text classification, question answering, and named entity recognition.
Here are some examples of companies that are developing encoder models based on BERT:
Hugging Face: Hugging Face is a company that develops open-source NLP libraries and tools. They have developed several models based on BERT, including DistilBERT, RoBERTa, and GPT-2.
Google: Google is the original developer of BERT, and they continue to work on improving the model. They have also developed other models based on BERT, such as ALBERT and ELECTRA.
OpenAI: OpenAI is a research organization that has developed several Transformer-based models, including GPT-3, which is based on the Transformer architecture used in BERT.
Microsoft: Microsoft has developed several models based on BERT, including MT-DNN (Multi-Task Deep Neural Network) and UniLM (Unified Language Model).
Facebook: Facebook has developed several models based on BERT, including XLM (Cross-lingual Language Model) and RoBERTa.
These companies and others are developing encoder models based on Transformers and BERT to improve NLP tasks and create new applications that rely on language processing.
เบิร์ต และผองเพื่อน BERT, RoBERTa, DistilBERT, XLNet
มาทำความรู้จัก และเปรียบเทียบจุดเด่นระหว่าง Encoder ของทรานฟอร์เมอร์สี่ตัว ได้แก่ BERT, RoBERTa, DistilBERT และ XLNet กัน
XLNet เป็นทรานฟอร์เมอร์แบบสองทิศทางขนาดใหญ่ที่ใช้วิธีการเทรนนิ่งที่ได้รับการปรับปรุง ดาค้าเซ็ตขนาดใหญ่ขึ้น และพลังการคำนวณที่มากขึ้น เพื่อให้ได้เมตริกการคาดการณ์ที่ดีกว่า BERT ในงาน 20 ภาษา XLNet แนะนำการสร้างแบบจำลองภาษาการเรียงสับเปลี่ยน ซึ่งมีการทำนายโทเค็นทั้งหมดแต่อยู่ในลำดับแบบสุ่ม เพื่อเรียนรู้ความสัมพันธ์แบบสองทิศทางระหว่างคำได้ดียิ่งขึ้น นอกจากนี้ Transformer XL ยังถูกใช้เป็นสถาปัตยกรรมพื้นฐาน ซึ่งแสดงประสิทธิภาพที่ดี แม้ไม่มีการเทรนนิ่งตามการเปลี่ยนแปลง XLNet ได้รับการเทรนนิ่งด้วยข้อมูลข้อความมากกว่า 130 GB และชิป TPU 512 ชิ้นที่ทำงานเป็นเวลา 2.5 วัน ซึ่งทั้งสองชิปมีขนาดใหญ่กว่า BERT มาก
BERT เป็นโมดูลแปลงข้อมูลให้เป็นเวกเตอร์คณิตศาสตร์ของ Transformer แบบสองทิศทาง ที่ใช้ pre-trained กับดาต้าเซ็ตจำนวนมากที่ไม่มีป้ายกำกับ เพื่อเรียนรู้การแสดงภาษาที่สามารถใช้เพื่อปรับแต่งสำหรับงานแมชชีนเลิร์นนิงเฉพาะเจาะจง BERT มีประสิทธิภาพเหนือกว่าเทคโนโลยีล้ำสมัยในงานที่ท้าทายมากมาย โดยใช้งานก่อนการฝึกอบรมแบบใหม่ของ Masked Language Model และ Next Structure Prediction พร้อมด้วยข้อมูลจำนวนมากและพลังการประมวลผลของ Google มีการเสนอวิธีการหลายวิธีในการปรับปรุง BERT ทั้งเมตริกการคาดการณ์หรือความเร็วในการคำนวณ แต่ไม่ใช่ทั้งสองอย่าง
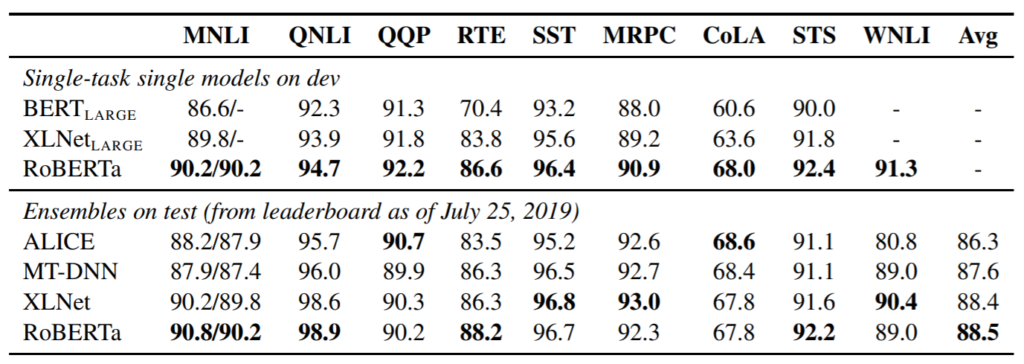
RoBERTa เป็นแนวทาง BERT ที่ได้รับการปรับปรุงจาก Facebook ได้ optimize การ pretrain MLM ของ bert ดั้งเดิม รวมทั้งเพิ่ม pretrained dataset ให้ใหญ่กว่าเดิมมาก ทำให้ได้ผลลัพธ์ดีกว่า BERT ดาต้าเซ็ตเพิ่มขึ้น 1,000% และพลังการประมวลผล เพื่อปรับปรุงขั้นตอนการฝึกอบรม RoBERTa จะลบงาน Next Sentence Prediction (NSP) ออกจากการฝึกอบรมล่วงหน้าของ BERT และแนะนำการมาสก์แบบไดนามิกเพื่อให้โทเค็นที่สวมหน้ากากเปลี่ยนแปลงระหว่างช่วงเวลาการฝึกอบรม RoBERTa ใช้ข้อความ 160 GB สำหรับการฝึกอบรมล่วงหน้า รวมถึง Books Corpus และ Wikipedia ภาษาอังกฤษ 16GB ที่ใช้ใน BERT ข้อมูลเพิ่มเติมประกอบด้วยชุดข้อมูล CommonCrawl News (63 ล้านบทความ 76 GB) คลังข้อความเว็บ (38 GB) และเรื่องราวจาก Common Crawl (31 GB) เมื่อรวมกับ 1024 V100 Tesla GPU ที่ทำงานเป็นเวลาหนึ่งวัน นำไปสู่การฝึกฝน RoBERTa ล่วงหน้า ผลที่ได้คือ RoBERTa มีประสิทธิภาพเหนือกว่าทั้ง BERT และ XLNet ในผลการวัดประสิทธิภาพ GLUE
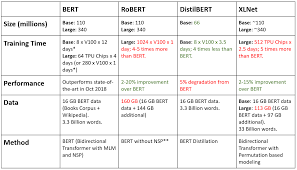
DitilBERT pretrain ด้วยเทคนิก distillation นั่นคือเทรนบน soft-labels ของ Bert-large ซึ่งทำให้มีความแม่นยำน้อยกว่า Bert-base ไม่มาก โดยคงประสิทธิภาพไว้ 95% แตามีขนาดเล็กกว่ามาก ใช้จำนวนพารามิเตอร์เพียงครึ่งเดียว โดยเฉพาะอย่างยิ่ง มันไม่มีการฝังประเภทโทเค็น ตัวพูลเลอร์ และเก็บเลเยอร์จาก BERT ของ Google ไว้เพียงครึ่งเดียวเท่านั้น
หากต้องการความเร็วที่เร็วกว่า โดยยอมประนีประนอม กับความถูกต้องแม่นยำที่ลดลงเล็กน้อย DistilBERT เป็นตัวเลือกที่ดี แต่ถ้าเน้น ความถูกต้องแม่นยำ เมตริกการคาดการณ์ที่ดีที่สุดจาก RoBERTa ของ Facebook คือทางเลือกของคุณ ในทางทฤษฎี การเทรนนิ่งดาต้าเซ็ตของ XLNet น่าจะรับมือกับการเปลี่ยนแปลงได้ดี และใช้งานได้ดีในระยะยาว อย่างไรก็ตาม หากไม่ต้องการคุณสมบัติเพิ่มเติมใดๆ ข้างต้น BERT จะยังเป็นทางเลือกพื้นฐานที่ดีเยี่ยมในการทำงาน