การทำงานที่ก้าวล้ำของ Neural Module Networks ในปีก่อนๆ มีเป้าหมายที่จะแบ่งงานออกเป็นโมดูลที่ง่ายขึ้น ผ่านการฝึกอบรมตั้งแต่ต้นจนจบโดยใช้โมดูลที่ได้รับการกำหนดค่าใหม่สำหรับปัญหาต่างๆ แต่ละโมดูลจะเรียนรู้จุดประสงค์ที่แท้จริงและสามารถนำมาใช้ซ้ำได้ อย่างไรก็ตาม ต้องใช้ความพยายามอย่างมากในการใช้กลยุทธ์นี้ในโลกแห่งความเป็นจริงเนื่องจากปัญหาหลายประการ โดยเฉพาะอย่างยิ่งการพัฒนาโปรแกรมจำเป็นต้องมีการเรียนรู้เสริมตั้งแต่เริ่มต้นหรือพึ่งพาโปรแกรมแยกวิเคราะห์ภาษาธรรมชาติที่ปรับแต่งด้วยมือ ทำให้โปรแกรมเหล่านี้มีความท้าทายในการปรับให้เหมาะสม การสร้างโปรแกรมถูกจำกัดขอบเขตอย่างมากในแต่ละสถานการณ์ การฝึกอบรมทำได้ยากขึ้นมากเนื่องจากการเรียนรู้แบบจำลองการรับรู้ควบคู่ไปกับตัวสร้างโปรแกรม ซึ่งมักจะไม่สามารถจัดเตรียมโครงสร้างโมดูลาร์ที่ต้องการได้
Meet ViperGPT: A Python Framework that Combines Vision and Language Models Using Code Generation to Achieve State-of-the-Art Results. The groundbreaking work of Neural Module Networks in prior years aimed to break down jobs into simpler modules. Through training from beginning to finish using modules that were reconfigured for various issues, each module would learn its true purpose and become reusable.
พบกับ ViperGPT: Python Framework ที่รวมวิสัยทัศน์และโมเดลภาษา โดยใช้การสร้างโค้ดเพื่อผลลัพธ์ระดับ State-of-the-Art
การทำงานที่ก้าวล้ำของ Neural Module Networks ในปีก่อนๆ มีเป้าหมายที่จะแบ่งงานออกเป็นโมดูลที่ง่ายขึ้น ผ่านการฝึกอบรมตั้งแต่ต้นจนจบโดยใช้โมดูลที่ได้รับการกำหนดค่าใหม่สำหรับปัญหาต่างๆ แต่ละโมดูลจะเรียนรู้จุดประสงค์ที่แท้จริงและสามารถนำมาใช้ซ้ำได้
อย่างไรก็ตาม ต้องใช้ความพยายามอย่างมากในการใช้กลยุทธ์นี้ในโลกแห่งความเป็นจริงเนื่องจากปัญหาหลายประการ โดยเฉพาะอย่างยิ่งการพัฒนาโปรแกรมจำเป็นต้องมีการเรียนรู้เสริมตั้งแต่เริ่มต้นหรือพึ่งพาโปรแกรมแยกวิเคราะห์ภาษาธรรมชาติที่ปรับแต่งด้วยมือ ทำให้โปรแกรมเหล่านี้มีความท้าทายในการปรับให้เหมาะสม การสร้างโปรแกรมถูกจำกัดขอบเขตอย่างมากในแต่ละสถานการณ์ การฝึกอบรมทำได้ยากขึ้นมากเนื่องจากการเรียนรู้แบบจำลองการรับรู้ควบคู่ไปกับตัวสร้างโปรแกรม ซึ่งมักจะไม่สามารถจัดเตรียมโครงสร้างโมดูลาร์ที่ต้องการได้
ตัวอย่างเช่น ให้เราทำตามคำแนะนำ เด็กแต่ละคนสามารถกินมัฟฟินได้กี่ชิ้นจึงจะยุติธรรม (ดูรูปที่ 1 (บนสุด)) ค้นหาเด็กๆ และมัฟฟินในภาพ นับจำนวนที่มีแต่ละชิ้น จากนั้นตัดสินใจแบ่งโดยใช้ตรรกะที่ “ยุติธรรม” หมายถึงการแบ่งที่เท่าเทียมกัน
เพื่อให้เข้าใจสภาพแวดล้อมที่มองเห็นได้ เป็นเรื่องปกติที่ผู้คนจะผสมผสานหลายช่วงเข้าด้วยกัน ถึงกระนั้น โมเดลแบบ end-to-end ซึ่งไม่ได้ใช้เหตุผลเชิงองค์ประกอบตามธรรมชาตินี้ ยังคงเป็นกลยุทธ์ที่มีอำนาจเหนือกว่าในการมองเห็นด้วยคอมพิวเตอร์ แม้ว่าระเบียบวินัยจะมีความก้าวหน้าอย่างมากในงานเฉพาะอย่าง เช่น การระบุวัตถุและการประมาณค่าเชิงลึก แต่วิธีการแบบ end-to-end สำหรับงานที่ซับซ้อนยังคงต้องเรียนรู้เพื่อให้งานทุกอย่างสำเร็จโดยปริยายในระหว่างการรันไปข้างหน้าของโครงข่ายประสาทเทียม
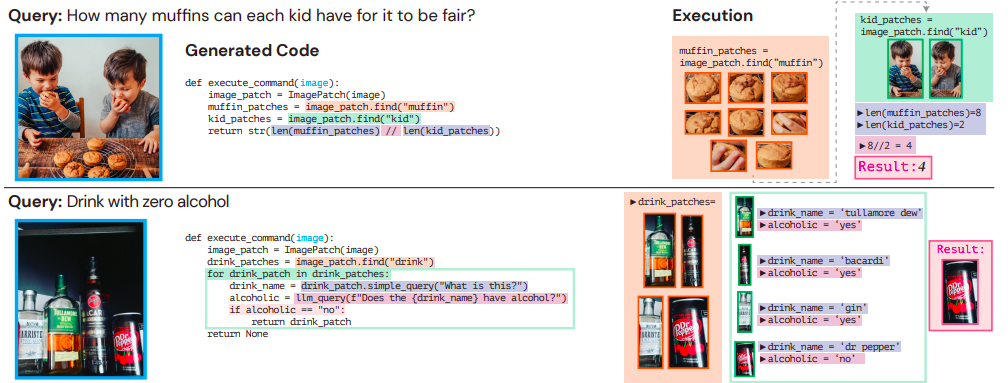
สิ่งนี้ล้มเหลวในการใช้ประโยชน์จากความก้าวหน้าในงานการมองเห็นพื้นฐานในหลายระดับ ถึงกระนั้นก็ไม่สนใจว่าคอมพิวเตอร์สามารถดำเนินการทางคณิตศาสตร์ได้อย่างง่ายดาย (เช่น การหาร) โดยไม่ต้องเรียนรู้ด้วยเครื่อง พวกเขาไม่สามารถพึ่งพาแบบจำลองของเซลล์ประสาทในการสรุปจำนวนมัฟฟินหรือจำนวนลูกที่แตกต่างกันอย่างเป็นระบบได้ โมเดลแบบ end-to-end ยังส่งผลให้เกิดการตัดสินที่คลุมเครือเนื่องจากเป็นไปไม่ได้ที่จะตรวจสอบผลลัพธ์ของแต่ละเฟสเพื่อระบุความล้มเหลว วิธีนี้ใช้ไม่ได้ผลขึ้นเรื่อยๆ เนื่องจากโมเดลได้รับข้อมูลมากขึ้นและต้องใช้การคำนวณมากเกินไป พวกเขาจะตั้งเป้าที่จะรวมโมเดลปัจจุบันเข้าด้วยกันใหม่ในรูปแบบใหม่เพื่อทำงานใหม่ให้สำเร็จโดยไม่ต้องฝึกฝนเพิ่มเติม เหตุใดพวกเขาจึงไม่สามารถออกแบบโซลูชันโมดูลาร์ที่คล้ายกันสำหรับงานที่ยากขึ้นได้
ในการศึกษานี้ นักวิจัยจากมหาวิทยาลัยโคลัมเบียแนะนำ ViperGPT1 ซึ่งเป็นเฟรมเวิร์กที่หลีกเลี่ยงข้อจำกัดเหล่านี้โดยใช้โมเดลภาษาขนาดใหญ่ที่สร้างโค้ด (เช่น GPT-3 Codex) เพื่อสร้างโมเดลการมองเห็นอย่างคล่องแคล่วบนข้อความค้นหาที่ระบุงาน สำหรับคำถามแต่ละข้อ จะสร้างโปรแกรมพิเศษที่ยอมรับภาพถ่ายหรือวิดีโอเป็นอาร์กิวเมนต์ และส่งคำตอบสำหรับคำถามเกี่ยวกับรูปภาพหรือวิดีโอนั้น พวกเขาแสดงให้เห็นว่าการสร้างแอปพลิเคชันเหล่านี้ต้องการเพียงให้ Codex เป็น API ที่เปิดเผยคุณลักษณะด้านภาพต่างๆ (เช่น ตำแหน่งและความลึกของการคำนวณ) เช่นเดียวกับที่วิศวกรสามารถจัดเตรียมได้ แบบจำลองสามารถให้เหตุผลเกี่ยวกับการใช้ฟังก์ชันเหล่านี้และสร้างตรรกะที่จำเป็นได้ด้วยการฝึกอบรมโค้ดก่อนหน้านี้ การค้นพบของพวกเขาแสดงให้เห็นว่ากลยุทธ์ที่ตรงไปตรงมานี้ให้ประสิทธิภาพการทำงานแบบ Zero-shot ที่ยอดเยี่ยม (กล่าวคือ ไม่มีการฝึกอบรมเกี่ยวกับภาพเฉพาะงาน) วิธีการเฉพาะของพวกเขามีข้อดีหลายประการ:
การอ่านที่ได้รับการสนับสนุน: การใช้ประโยชน์จาก TensorLeap เพื่อการเรียนรู้การถ่ายโอนที่มีประสิทธิภาพ: การเอาชนะช่องว่างของโดเมน
1. สามารถตีความได้เนื่องจากขั้นตอนทั้งหมดถูกกำหนดอย่างชัดเจนว่าเป็นการเรียกใช้ฟังก์ชันในโค้ดที่มีค่ากลางที่มองเห็นได้
2. เป็นตรรกะเพราะใช้การดำเนินการทางตรรกะและคณิตศาสตร์ที่มีอยู่ใน Python อย่างชัดเจน
3. สามารถปรับเปลี่ยนได้เนื่องจากสามารถรวมวิสัยทัศน์หรือโมดูลภาษาใด ๆ ได้อย่างง่ายดายโดยการเพิ่มเฉพาะคำจำกัดความของโมดูลที่เกี่ยวข้องไปยัง API
4. การจัดองค์ประกอบ แบ่งกิจกรรมออกเป็นงานย่อยย่อยๆ ที่เสร็จสิ้นทีละขั้นตอน
5. ปรับให้เข้ากับความก้าวหน้าในพื้นที่เนื่องจากการปรับปรุงโมดูลใด ๆ ที่จ้างงานจะเพิ่มประสิทธิภาพโดยตรงของเทคนิค
6. ไม่จำเป็นต้องฝึกอบรมซ้ำ (หรือปรับแต่ง) โมเดลใหม่สำหรับแต่ละกิจกรรมล่าสุด
7. เป็นแบบทั่วไปเนื่องจากรวมงานทั้งหมดไว้ในระบบเดียว
ดังนั้นผลงานของพวกเขามีดังนี้:
* การใช้ข้อดีที่ระบุไว้ข้างต้น ทำให้มีเฟรมเวิร์กที่ตรงไปตรงมาสำหรับการจัดการการสอบถามด้วยภาพที่ซับซ้อน โดยผสมผสานโมเดลการสร้างโค้ดเข้ากับการมองเห็นด้วย API และตัวแปลภาษา Python
* พวกเขาได้รับคะแนน Zero-shot ที่ล้ำสมัยในงานที่เกี่ยวข้องกับการลงกราวด์ด้วยภาพ การตอบคำถามด้วยรูปภาพ และการตอบคำถามด้วยวิดีโอ ซึ่งแสดงให้เห็นว่าความสามารถในการตีความนี้ช่วยปรับปรุงมากกว่าลดทอนประสิทธิภาพการทำงาน
* เพื่อสนับสนุนการศึกษาในด้านนี้ พวกเขาจัดเตรียมห้องสมุด Python ที่ช่วยให้สามารถสร้างโปรแกรมสำหรับงานด้านภาพได้อย่างรวดเร็ว และจะเป็นแบบโอเพ่นซอร์สหลังจากการเผยแพร่