นักวิจัยจากสถาบันเทคโนโลยีแมสซาชูเซตส์ (MIT) ได้พัฒนาเทคนิคการเรียนรู้ของเครื่องแบบใหม่ที่เรียกว่า Learned Linear Growth Operator (LiGO) ซึ่งสามารถฝึกโมเดลการเรียนรู้ของเครื่องขนาดใหญ่โดยใช้เวลาน้อยลงและใช้เงินน้อยลง LiGO ขยายโมเดลที่ใหญ่ขึ้นจากโมเดลที่เล็กกว่า โดยใช้การเรียนรู้ของเครื่องเพื่อเข้ารหัสความรู้ที่โมเดลที่เล็กกว่าได้รับแล้ว วิธีการนี้เรียนรู้ที่จะขยายความกว้างและความลึกของเครือข่ายที่ใหญ่ขึ้นจากพารามิเตอร์ของเครือข่ายที่เล็กกว่าด้วยวิธีที่ขับเคลื่อนด้วยข้อมูล ซึ่งช่วยประหยัดค่าใช้จ่ายด้านการคำนวณประมาณ 50% ที่จำเป็นในการฝึกโมเดลภาษาและการมองเห็นขนาดใหญ่
Researchers from the Massachusetts Institute of Technology (MIT) have developed a new machine learning technique, called a Learned Linear Growth Operator (LiGO), which can train large machine learning models in less time and for less money. LiGO grows a larger model from a smaller one, using machine learning to encode the knowledge the smaller model has already gained. The method learns to expand the width and depth of a larger network from the parameters of a smaller network in a data-driven way, saving around 50% of the computational costs required to train large language and vision models.
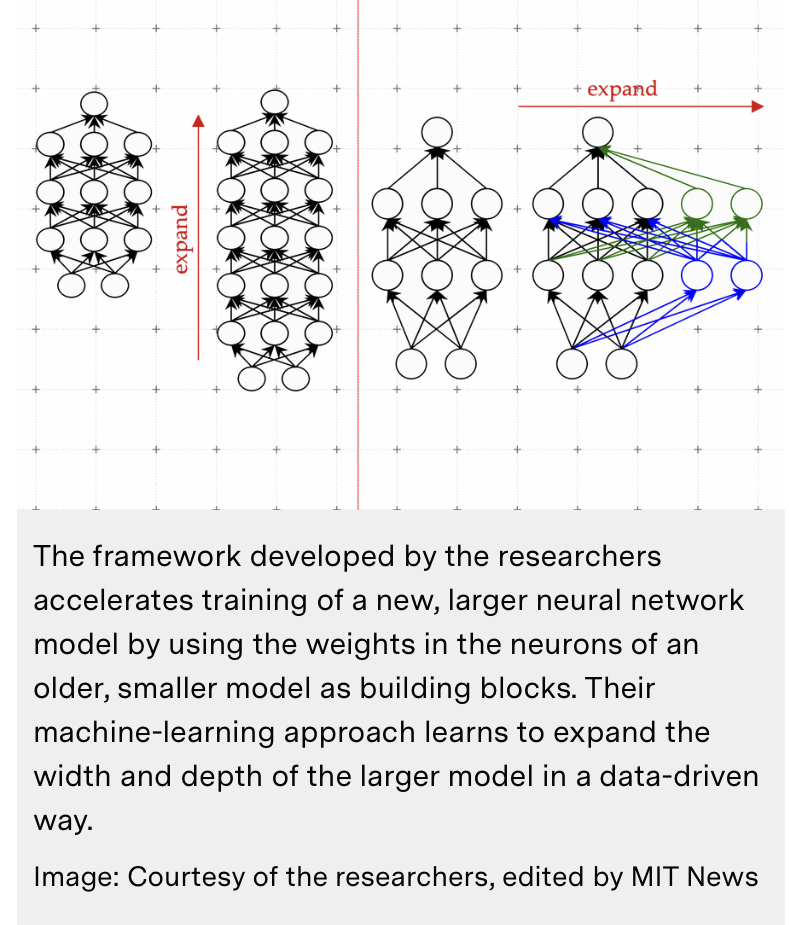
การเรียนรู้เพื่อพัฒนาโมเดลแมชชีนเลิร์นนิง
เทคนิค LiGO ใหม่ช่วยเร่งการฝึกอบรมโมเดลแมชชีนเลิร์นนิงขนาดใหญ่ ลดค่าใช้จ่ายทางการเงินและสิ่งแวดล้อมในการพัฒนาแอปพลิเคชัน AI
ไม่มีความลับใดที่ ChatGPT ของ OpenAI มีความสามารถที่น่าทึ่ง ตัวอย่างเช่น แชทบอทสามารถเขียนบทกวีที่คล้ายกับโคลงของเชกสเปียร์หรือแก้ไขโค้ดสำหรับโปรแกรมคอมพิวเตอร์ ความสามารถเหล่านี้เกิดขึ้นได้จากโมเดลแมชชีนเลิร์นนิงขนาดใหญ่ที่ ChatGPT สร้างขึ้น นักวิจัยพบว่าเมื่อโมเดลเหล่านี้มีขนาดใหญ่พอ ความสามารถพิเศษก็ปรากฏขึ้น
แต่รุ่นที่ใหญ่กว่าก็ต้องใช้เวลาและเงินมากขึ้นในการฝึกอบรม กระบวนการฝึกอบรมเกี่ยวข้องกับการแสดงตัวอย่างหลายแสนล้านตัวอย่างต่อแบบจำลอง การรวบรวมข้อมูลจำนวนมากเป็นกระบวนการที่เกี่ยวข้องในตัวเอง จากนั้นต้นทุนทางการเงินและสิ่งแวดล้อมในการใช้งานคอมพิวเตอร์ที่ทรงพลังหลายเครื่องเป็นเวลาหลายวันหรือหลายสัปดาห์เพื่อฝึกโมเดลที่อาจมีพารามิเตอร์หลายพันล้านตัว

“เป็นที่คาดกันว่าโมเดลการฝึกอบรมตามระดับของ ChatGPT ที่ถูกตั้งสมมติฐานว่าจะดำเนินการอาจใช้เงินหลายล้านดอลลาร์สำหรับการฝึกอบรมเพียงครั้งเดียว เราสามารถปรับปรุงประสิทธิภาพของวิธีการฝึกอบรมเหล่านี้เพื่อให้เรายังคงได้รับแบบจำลองที่ดีโดยใช้เวลาน้อยลงและใช้เงินน้อยลงได้หรือไม่ เราเสนอที่จะทำเช่นนี้โดยใช้ประโยชน์จากโมเดลภาษาขนาดเล็กที่ได้รับการฝึกฝนมาก่อนหน้านี้” Yoon Kim ผู้ช่วยศาสตราจารย์ในภาควิชาวิศวกรรมไฟฟ้าและวิทยาการคอมพิวเตอร์ของ MIT และสมาชิกของ Computer Science and Artificial Intelligence Laboratory (CSAIL) กล่าว
แทนที่จะทิ้งรุ่นก่อนหน้าของรุ่น Kim และผู้ร่วมงานของเขาใช้มันเป็นพื้นฐานในการสร้างโมเดลใหม่ วิธีการของพวกเขาใช้แมชชีนเลิร์นนิงเพื่อเรียนรู้ที่จะ “ขยาย” โมเดลที่ใหญ่กว่าจากโมเดลที่เล็กกว่าด้วยวิธีที่เข้ารหัสความรู้ที่โมเดลที่เล็กกว่าได้รับไปแล้ว สิ่งนี้ทำให้การฝึกอบรมรุ่นใหญ่เร็วขึ้น
เทคนิคของพวกเขาช่วยประหยัดต้นทุนการคำนวณที่ต้องใช้ในการฝึกโมเดลขนาดใหญ่ได้ประมาณ 50 เปอร์เซ็นต์ เมื่อเทียบกับวิธีการฝึกโมเดลใหม่ตั้งแต่ต้น นอกจากนี้ แบบจำลองที่ได้รับการฝึกฝนโดยใช้วิธีการของ MIT มีประสิทธิภาพเทียบเท่าหรือดีกว่าแบบจำลองที่ได้รับการฝึกฝนด้วยเทคนิคอื่นๆ ที่ใช้แบบจำลองขนาดเล็กกว่าเพื่อให้สามารถฝึกอบรมแบบจำลองขนาดใหญ่ได้เร็วขึ้น
การลดเวลาที่ใช้ในการฝึกโมเดลขนาดใหญ่สามารถช่วยให้นักวิจัยก้าวหน้าเร็วขึ้นด้วยค่าใช้จ่ายที่น้อยลง ขณะเดียวกันก็ลดการปล่อยคาร์บอนที่เกิดขึ้นระหว่างกระบวนการฝึกอบรมด้วย
นอกจากนี้ยังช่วยให้กลุ่มวิจัยขนาดเล็กสามารถทำงานร่วมกับแบบจำลองขนาดใหญ่เหล่านี้ได้ ซึ่งอาจเป็นการเปิดประตูสู่ความก้าวหน้าใหม่ๆ มากมาย “ในขณะที่เราต้องการทำให้เทคโนโลยีประเภทนี้เป็นประชาธิปไตย การทำให้การฝึกอบรมเร็วขึ้นและราคาถูกลงจะมีความสำคัญมากขึ้น” คิม ผู้เขียนอาวุโสของบทความเกี่ยวกับเทคนิคนี้กล่าว
คิมและนักศึกษาปริญญาโท Lucas Torroba Hennigen เขียนบทความร่วมกับผู้เขียนนำ Peihao Wang นักศึกษาระดับบัณฑิตศึกษาจาก University of Texas at Austin รวมถึงคนอื่นๆ ที่ MIT-IBM Watson AI Lab และ Columbia University งานวิจัยจะถูกนำเสนอในการประชุมระหว่างประเทศว่าด้วยการเป็นตัวแทนการเรียนรู้ ใหญ่กว่าดีกว่า โมเดลภาษาขนาดใหญ่ เช่น GPT-3 ซึ่งเป็นแกนหลักของ ChatGPT สร้างขึ้นโดยใช้สถาปัตยกรรมโครงข่ายประสาทที่เรียกว่าทรานส์ฟอร์ม โครงข่ายประสาทเทียมที่มีพื้นฐานมาจากสมองของมนุษย์อย่างหลวมๆ ประกอบด้วยชั้นต่างๆ ของโหนดที่เชื่อมต่อกันหรือที่เรียกว่า “เซลล์ประสาท” เซลล์ประสาทแต่ละตัวมีพารามิเตอร์ซึ่งเป็นตัวแปรที่เรียนรู้ระหว่างกระบวนการฝึกอบรมที่เซลล์ประสาทใช้ในการประมวลผลข้อมูล สถาปัตยกรรมของ Transformer มีเอกลักษณ์เฉพาะตัว เนื่องจากโมเดลโครงข่ายประสาทเทียมประเภทนี้มีขนาดใหญ่ขึ้น จึงให้ผลลัพธ์ที่ดีกว่ามาก “สิ่งนี้นำไปสู่การแข่งขันด้านอาวุธของบริษัทต่างๆ ที่พยายามฝึกหม้อแปลงขนาดใหญ่ขึ้นและใหญ่ขึ้นในชุดข้อมูลที่ใหญ่ขึ้นและใหญ่ขึ้น มากกว่าสถาปัตยกรรมอื่น ๆ ดูเหมือนว่าเครือข่ายหม้อแปลงจะดีขึ้นมากเมื่อปรับขนาด เราแค่ไม่แน่ใจว่าทำไมถึงเป็นเช่นนี้” คิมกล่าว

โมเดลเหล่านี้มักมีพารามิเตอร์ที่สามารถเรียนรู้ได้หลายร้อยล้านหรือหลายพันล้านตัว การฝึกอบรมพารามิเตอร์เหล่านี้ตั้งแต่เริ่มต้นมีค่าใช้จ่ายสูง ดังนั้นนักวิจัยจึงพยายามเร่งกระบวนการ เทคนิคหนึ่งที่มีประสิทธิภาพเรียกว่าการเติบโตของแบบจำลอง เมื่อใช้วิธีการขยายแบบจำลอง นักวิจัยสามารถเพิ่มขนาดของหม้อแปลงได้โดยการคัดลอกเซลล์ประสาท หรือแม้แต่เลเยอร์ทั้งหมดของเครือข่ายเวอร์ชันก่อนหน้า จากนั้นจึงวางซ้อนกันไว้ด้านบน พวกเขาสามารถทำให้เครือข่ายกว้างขึ้นโดยการเพิ่มเซลล์ประสาทใหม่ลงในเลเยอร์หรือทำให้ลึกขึ้นโดยการเพิ่มเลเยอร์ของเซลล์ประสาทเพิ่มเติม
ตรงกันข้ามกับแนวทางการเติบโตของโมเดลก่อนหน้านี้ พารามิเตอร์ที่เกี่ยวข้องกับเซลล์ประสาทใหม่ในหม้อแปลงขยายไม่ได้เป็นเพียงสำเนาของพารามิเตอร์ของเครือข่ายที่เล็กกว่าเท่านั้น Kim อธิบาย แต่จะเรียนรู้การรวมกันของพารามิเตอร์ของโมเดลที่เล็กกว่า เรียนรู้ที่จะเติบโต
Kim และผู้ร่วมงานของเขาใช้แมชชีนเลิร์นนิงเพื่อเรียนรู้การทำแผนที่เชิงเส้นของพารามิเตอร์ของโมเดลขนาดเล็ก แผนที่เชิงเส้นนี้เป็นการดำเนินการทางคณิตศาสตร์ที่แปลงชุดของค่าอินพุต ในกรณีนี้คือพารามิเตอร์ของโมเดลที่เล็กกว่า ไปเป็นชุดของค่าเอาต์พุต ในกรณีนี้คือพารามิเตอร์ของโมเดลที่ใหญ่กว่า วิธีการของพวกเขาซึ่งเรียกว่า Linear Growth Operator (LiGO) ที่เรียนรู้แล้ว เรียนรู้ที่จะขยายความกว้างและความลึกของเครือข่ายขนาดใหญ่จากพารามิเตอร์ของเครือข่ายขนาดเล็กด้วยวิธีที่ขับเคลื่อนด้วยข้อมูล แต่แบบจำลองที่เล็กกว่านั้นอาจมีขนาดค่อนข้างใหญ่ — บางทีอาจมีพารามิเตอร์เป็นร้อยล้านตัว — และนักวิจัยอาจต้องการสร้างแบบจำลองที่มีพารามิเตอร์เป็นพันล้านตัว
ดังนั้น เทคนิค LiGO จึงแบ่งแผนที่เชิงเส้นออกเป็นชิ้นเล็กๆ ที่อัลกอริธึมการเรียนรู้ของเครื่องสามารถจัดการได้ LiGO ยังขยายความกว้างและความลึกพร้อมกัน ซึ่งทำให้มีประสิทธิภาพมากกว่าวิธีอื่นๆ ผู้ใช้สามารถปรับความกว้างและความลึกที่ต้องการให้โมเดลขนาดใหญ่ขึ้นได้ เมื่อป้อนโมเดลขนาดเล็ก และพารามิเตอร์ของโมเดล Kim อธิบาย เมื่อพวกเขาเปรียบเทียบเทคนิคของพวกเขากับกระบวนการฝึกฝนโมเดลใหม่ ตั้งแต่เริ่มต้น ตลอดจนวิธีการเติบโตของโมเดล มันเร็วกว่าพื้นฐานทั้งหมด วิธีการของพวกเขาช่วยประหยัดค่าใช้จ่ายด้านการคำนวณได้ประมาณ 50 เปอร์เซ็นต์ที่จำเป็นในการฝึกอบรมทั้งการมองเห็นและโมเดลภาษา ในขณะที่มักจะปรับปรุงประสิทธิภาพ
นักวิจัยยังพบว่าพวกเขาสามารถใช้ LiGO เพื่อเร่งการฝึกทรานส์ฟอร์เมอร์ได้ แม้ว่าพวกเขาจะไม่สามารถเข้าถึงโมเดลที่มีขนาดเล็กกว่าและได้รับการฝึกฝนมาก่อนก็ตาม “ฉันรู้สึกประหลาดใจที่วิธีการทั้งหมด รวมทั้งของเราดีขึ้นมากเพียงใด เมื่อเทียบกับการเริ่มต้นแบบสุ่ม การฝึกฝนตั้งแต่เริ่มต้น” Kim พูดว่า. ในอนาคต Kim และผู้ร่วมงานของเขารอคอยที่จะนำ LiGO ไปใช้กับโมเดลที่ใหญ่ขึ้น งานนี้ได้รับทุนบางส่วนจาก MIT-IBM Watson AI Lab, Amazon, IBM Research AI Hardware Center, Center for Computational Innovation at Rensselaer Polytechnic Institute และ US Army Research Office.
