Dreamix เป็นเฟรมเวิร์กปัญญาประดิษฐ์ (AI) แบบใหม่ สำหรับการตัดต่อวิดีโอแบบข้อความแนะนำ (text-guided video editing) ซึ่งใช้ text-conditioned video diffusion model แบบมีเงื่อนไขข้อความเพื่อรักษาความเที่ยงตรงสูงของวิดีโออินพุตที่กำหนด ผู้เขียนใช้วิดีโอต้นฉบับในเวอร์ชันที่ลดคุณภาพลง แทนที่จะป้อน pure noise เป็นค่าเริ่มต้นให้กับโมเดล และ fine-tune ปรับแต่งโมเดล generation อย่างละเอียดในวิดีโอต้นฉบับเพื่อปรับปรุงความเที่ยงตรงให้ดียิ่งขึ้น
เพื่อแก้ไขปัญหาการขาดความสามารถในการตัดต่อภาพเคลื่อนไหว พวกเขาแนะนำแนวทางใหม่ที่เรียกว่าการปรับละเอียดแบบผสม (mixed finetuning) โดยที่ Video Diffusion Models ได้รับการปรับแต่งในแต่ละเฟรมวิดีโออินพุตโดยไม่คำนึงถึงคำสั่งชั่วคราว (temporal order) Dreamix แสดงให้เห็นถึงการปรับปรุงคุณภาพการแก้ไขการเคลื่อนไหวอย่างมีนัยสำคัญเมื่อเทียบกับแนวทางที่ล้ำสมัย
Dreamix is a novel artificial intelligence (AI) framework for text-guided video editing that uses a text-conditioned video diffusion model to maintain high fidelity to the given input video. The authors use a degraded version of the original video instead of feeding pure noise as initialization to the model and fine-tune the generation model on the original video to improve the fidelity further. To address the issue of lack of motion editability, they suggest a new approach called mixed finetuning, where the Video Diffusion Models are finetuned on individual input video frames while disregarding the temporal order. Dreamix shows significant improvement in the quality of motion edits compared to state-of-the-art approaches.
พบกับ Dreamix: กรอบงานปัญญาประดิษฐ์ (AI) แบบใหม่สำหรับ Text-Guided Video Editing
การแปลงข้อความเป็นรูปภาพเป็นงานที่ท้าทายในการมองเห็นของคอมพิวเตอร์และการประมวลผลภาษาธรรมชาติ การสร้างเนื้อหาภาพคุณภาพสูงจากคำอธิบายที่เป็นข้อความจำเป็นต้องเข้าใจความสัมพันธ์ที่ซับซ้อนระหว่างภาษาและข้อมูลภาพ หากการแปลงข้อความเป็นรูปภาพเป็นสิ่งที่ท้าทายอยู่แล้ว การสังเคราะห์ข้อความเป็นวิดีโอจะขยายความซับซ้อนของการสร้างเนื้อหา 2 มิติเป็น 3 มิติ เนื่องจากการพึ่งพาชั่วคราวระหว่างเฟรมวิดีโอ
วิธีการแบบคลาสสิกในการจัดการกับเนื้อหาที่ซับซ้อนดังกล่าวคือการใช้ประโยชน์จากDiffusion models Diffusion models กลายเป็นเทคนิคที่มีประสิทธิภาพในการแก้ไขปัญหานี้ โดยใช้ประโยชน์จากพลังของโครงข่ายประสาทเทียมระดับลึกเพื่อสร้างภาพที่เหมือนจริงในภาพถ่ายซึ่งสอดคล้องกับคำอธิบายที่เป็นข้อความหรือเฟรมวิดีโอที่กำหนดโดยมีความสอดคล้องทางโลก
Diffusion models ทำงานโดยปรับแต่งเนื้อหาที่สร้างขึ้นซ้ำๆ ผ่านลำดับขั้นตอนการแพร่กระจาย โดยที่แบบจำลองจะเรียนรู้ที่จะจับการพึ่งพาที่ซับซ้อนระหว่างโดเมนข้อความและภาพ โมเดลเหล่านี้ได้แสดงผลลัพธ์ที่น่าประทับใจในช่วงไม่กี่ปีที่ผ่านมา โดยได้รับประสิทธิภาพการสังเคราะห์ข้อความเป็นรูปภาพและข้อความเป็นวิดีโอที่ล้ำสมัย
แม้ว่าโมเดลเหล่านี้จะนำเสนอกระบวนการสร้างสรรค์ใหม่ๆ แต่ส่วนใหญ่จะจำกัดอยู่ที่การสร้างภาพที่แปลกใหม่มากกว่าการแก้ไขภาพที่มีอยู่ แนวทางล่าสุดบางแนวทางได้รับการพัฒนาเพื่อเติมเต็มช่องว่างนี้ โดยเน้นการรักษาลักษณะเฉพาะของภาพ เช่น ลักษณะใบหน้า พื้นหลัง หรือพื้นหน้า ในขณะที่แก้ไขส่วนอื่นๆ สำหรับการตัดต่อวิดีโอ สถานการณ์จะเปลี่ยนไป จนถึงปัจจุบัน มีการใช้แบบจำลองเพียงไม่กี่แบบสำหรับงานนี้ และด้วยผลลัพธ์ที่หายาก ความดีของเทคนิคสามารถอธิบายได้จากการจัดตำแหน่ง ความเที่ยงตรง และคุณภาพ การจัดตำแหน่งหมายถึงระดับความสอดคล้องกันระหว่างข้อความป้อนเข้าและวิดีโอผลลัพธ์ ความเที่ยงตรงจะพิจารณาถึงระดับการรักษาเนื้อหาอินพุตต้นฉบับ (หรืออย่างน้อยในส่วนที่ไม่ได้อ้างถึงในข้อความแจ้ง) คุณภาพหมายถึงคำจำกัดความของภาพ เช่น การมีรายละเอียดที่ละเอียด
ส่วนที่ท้าทายที่สุดของการตัดต่อวิดีโอประเภทนี้คือการรักษาความสม่ำเสมอของเวลาระหว่างเฟรม เนื่องจากการประยุกต์ใช้วิธีการแก้ไขระดับภาพ (เฟรมต่อเฟรม) ไม่สามารถรับประกันความสอดคล้องดังกล่าวได้ จึงจำเป็นต้องใช้วิธีแก้ปัญหาที่แตกต่างกัน
แนวทางที่น่าสนใจในการจัดการกับงานตัดต่อวิดีโอมาจาก Dreamix ซึ่งเป็นเฟรมเวิร์กปัญญาประดิษฐ์ (AI) แบบแปลงข้อความเป็นรูปภาพที่อิงตามโมเดลการแพร่กระจาย ภาพรวมของ Dreamix แสดงไว้ด้านล่าง
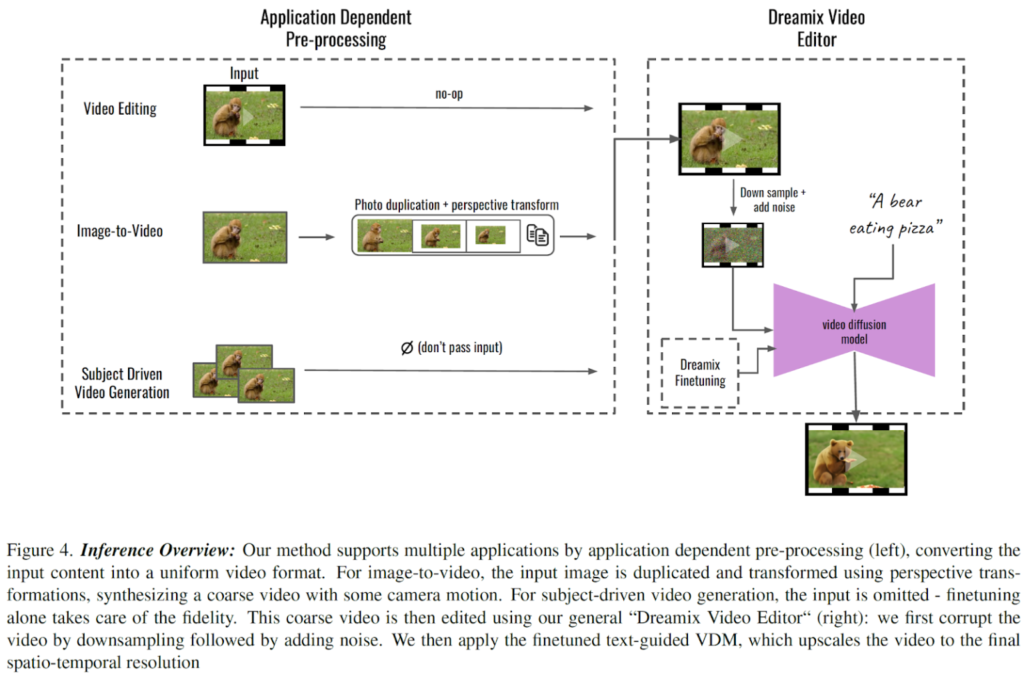
แกนหลักของวิธีนี้ คือการเปิดใช้งาน text-conditioned video diffusion model (VDM) เพื่อรักษาความเที่ยงตรงสูงของวิดีโออินพุตที่กำหนด แต่อย่างไร?
ประการแรก แทนที่จะทำตามวิธีการแบบคลาสสิกและป้อนสัญญาณรบกวนบริสุทธิ์เป็นการเริ่มต้นโมเดล ผู้เขียนใช้วิดีโอต้นฉบับในเวอร์ชันที่ลดคุณภาพลง เวอร์ชันนี้มีข้อมูลเชิงพื้นที่ต่ำและได้มาจากการลดขนาดและการเพิ่มสัญญาณรบกวน
ประการที่สอง โมเดลเจเนอเรชันได้รับการปรับแต่งในวิดีโอต้นฉบับเพื่อปรับปรุงความเที่ยงตรงให้ดียิ่งขึ้น
การปรับแต่งอย่างละเอียดทำให้มั่นใจได้ว่าโมเดลการเรียนรู้สามารถเข้าใจรายละเอียดปลีกย่อยของวิดีโอความละเอียดสูงได้ อย่างไรก็ตาม สมมติว่าโมเดลได้รับการปรับแต่งในวิดีโออินพุต ในกรณีนั้น อาจไม่สามารถแก้ไขการเคลื่อนไหวได้ เนื่องจากจะชอบการเคลื่อนไหวดั้งเดิมมากกว่าทำตาม text prompts.
เพื่อแก้ไขปัญหานี้ ผู้เขียนได้แนะนำแนวทางใหม่ที่เรียกว่าการปรับละเอียดแบบผสม ในการปรับแต่งแบบผสม Video Diffusion Models (VDMs) จะถูกปรับแต่งในแต่ละเฟรมวิดีโออินพุตโดยไม่คำนึงถึง temporal order สิ่งนี้ทำได้โดย masking temporal attention แล้ว Mixed finetuning นำไปสู่การปรับปรุงคุณภาพการแก้ไขภาพเคลื่อนไหวอย่างมีนัยสำคัญ
การเปรียบเทียบผลลัพธ์ระหว่าง Dreamix และแนวทางที่ล้ำสมัยแสดงไว้ด้านล่าง

นี่คือบทสรุปของ Dreamix ซึ่งเป็นเฟรมเวิร์ก AI แบบใหม่สำหรับการตัดต่อวิดีโอที่มีข้อความนำทาง (text-guided video editing) หากคุณสนใจหรือต้องการเรียนรู้เพิ่มเติมเกี่ยวกับเฟรมเวิร์กนี้ คุณสามารถค้นหาลิงก์ไปยังรายงานและหน้าโครงการ