โมเดลภาษาขนาดใหญ่ (LLM) เป็นโมเดลคอมพิวเตอร์ที่สามารถวิเคราะห์และสร้างข้อความได้ พวกเขาได้รับการฝึกฝนเกี่ยวกับข้อมูลที่เป็นข้อความจำนวนมหาศาลเพื่อเพิ่มประสิทธิภาพในงานต่างๆ เช่น การสร้างข้อความและแม้แต่การเขียนโค้ด
Large language models (LLMs) are computer models capable of analyzing and generating text. They are trained on a vast amount of textual data to enhance their performance in tasks like text generation and even coding.

โมเดล Multimodal LLMs : อนาคตของปัญญาประดิษฐ์ (AI)
LLM ในปัจจุบันส่วนใหญ่เป็นแบบข้อความเท่านั้น กล่าวคือ เชี่ยวชาญในแอปพลิเคชันแบบข้อความเท่านั้น และมีความสามารถจำกัดในการทำความเข้าใจข้อมูลประเภทอื่นๆ
ตัวอย่างของ LLM แบบข้อความเท่านั้น ได้แก่ GPT-3, BERT, RoBERTa เป็นต้น
ในทางตรงกันข้าม Multimodal LLMs รวมประเภทข้อมูลอื่นๆ เช่น รูปภาพ วิดีโอ เสียง และอินพุตทางประสาทสัมผัสอื่นๆ พร้อมกับข้อความ การผสานการทำงานหลายรูปแบบเข้ากับ LLM ช่วยแก้ไขข้อจำกัดบางประการของรูปแบบข้อความอย่างเดียวในปัจจุบัน และเปิดโอกาสสำหรับแอปพลิเคชันใหม่ที่ก่อนหน้านี้ไม่สามารถทำได้
GPT-4 ที่เพิ่งเปิดตัวโดย Open AI เป็นตัวอย่างของ Multimodal LLMs สามารถรับอินพุตรูปภาพและข้อความและได้แสดงประสิทธิภาพระดับมนุษย์ในเกณฑ์มาตรฐานมากมาย
การเพิ่มขึ้นของ AI แบบ Multimodal LLMs
ความก้าวหน้าของ AI หลายรูปแบบ สามารถให้เครดิตกับเทคนิคการเรียนรู้ของเครื่องที่สำคัญสองอย่าง: Representation learning และ transfer learning.
ด้วย Representation learning แบบจำลองสามารถพัฒนาตัวแทนที่ใช้ร่วมกันสำหรับรูปแบบทั้งหมด ในขณะที่ transfer learning ช่วยให้พวกเขาเรียนรู้ความรู้พื้นฐาน ก่อนการปรับแต่งอย่างละเอียดในโดเมนเฉพาะ
เทคนิคเหล่านี้มีความสำคัญต่อการทำให้ AI หลายรูปแบบเป็นไปได้และมีประสิทธิภาพ ดังที่เห็นได้จากความก้าวหน้าล่าสุด เช่น CLIP ซึ่งจัดแนวรูปภาพและข้อความ และ DALL·E 2 และ Stable Diffusion ซึ่งสร้างภาพคุณภาพสูงจากข้อความแจ้ง
เมื่อขอบเขตระหว่างรูปแบบข้อมูลต่างๆ มีความชัดเจนน้อยลง เราจึงคาดหวังได้ว่าแอปพลิเคชัน AI จำนวนมากขึ้น จะใช้ประโยชน์จากความสัมพันธ์ระหว่างรูปแบบต่างๆ จำนวนมาก ซึ่งบ่งบอกถึงการเปลี่ยนแปลงกระบวนทัศน์ในด้านนี้
แนวทางแบบเฉพาะกิจจะค่อยๆ ล้าสมัย และความสำคัญของการทำความเข้าใจความเชื่อมโยงระหว่างรูปแบบต่างๆ จะมีแต่จะเติบโตขึ้นเรื่อยๆ
การทำงานของ Multimodal LLMs
Text-only Language Models (LLMs) ขับเคลื่อนโดยโมเดล Transformer ซึ่งช่วยให้เข้าใจและสร้างภาษาได้ โมเดลนี้รับข้อความเข้าและแปลงเป็นการแสดงตัวเลขที่เรียกว่า “การฝังคำ-word embeddings” การฝังเหล่านี้ช่วยให้โมเดลเข้าใจความหมายและบริบทของข้อความ
โมเดล Transformer จะใช้สิ่งที่เรียกว่า “attention layers” เพื่อประมวลผลข้อความและกำหนดว่าคำต่างๆ ในข้อความอินพุตเกี่ยวข้องกันอย่างไร ข้อมูลนี้ช่วยให้โมเดลทำนายคำถัดไปที่เป็นไปได้มากที่สุดในเอาต์พุต
ในทางกลับกัน Multimodal LLMs ไม่เพียงแต่ทำงานกับข้อความเท่านั้น แต่ยังรวมถึงข้อมูลในรูปแบบอื่นๆ ด้วย เช่น รูปภาพ เสียง และวิดีโอ โมเดลเหล่านี้แปลงข้อความและประเภทข้อมูลอื่นๆ เป็นพื้นที่เข้ารหัสทั่วไป ซึ่งหมายความว่าโมเดลเหล่านี้สามารถประมวลผลข้อมูลทุกประเภทโดยใช้กลไกเดียวกัน ซึ่งช่วยให้โมเดลสร้างการตอบสนองที่รวมข้อมูลจากหลาย ๆ รูปแบบ นำไปสู่ผลลัพธ์ที่แม่นยำและตรงตามบริบทมากขึ้น
เหตุใดจึงต้องใช้ Multimodal Language Models
LLM แบบข้อความเท่านั้น เช่น GPT-3 และ BERT มีแอปพลิเคชันที่หลากหลาย เช่น การเขียนบทความ การเขียนอีเมล และการเขียนโค้ด อย่างไรก็ตาม วิธีการแบบข้อความอย่างเดียวนี้ได้เน้นถึงข้อจำกัดของโมเดลเหล่านี้ด้วย
แม้ว่าภาษาจะเป็นส่วนสำคัญของความฉลาดของมนุษย์ แต่มันก็เป็นเพียงด้านหนึ่งของความฉลาดของเราเท่านั้น ความสามารถทางปัญญาของเราพึ่งพาการรับรู้และความสามารถโดยไม่รู้ตัวอย่างมาก ซึ่งส่วนใหญ่กำหนดโดยประสบการณ์ในอดีตของเราและความเข้าใจเกี่ยวกับวิธีการทำงานของโลก
LLMs ที่ได้รับการฝึกฝนเฉพาะด้านข้อความนั้นมีข้อจำกัดโดยเนื้อแท้ในความสามารถในการรวมสามัญสำนึกและความรู้ทางโลก ซึ่งสามารถพิสูจน์ได้ว่าเป็นปัญหาสำหรับงานบางอย่าง การขยายชุดข้อมูลการฝึกอบรมสามารถช่วยได้ในระดับหนึ่ง แต่โมเดลเหล่านี้อาจยังพบช่องว่างที่คาดไม่ถึงในความรู้ของพวกเขา แนวทางต่อเนื่องหลายรูปแบบสามารถจัดการกับความท้าทายเหล่านี้ได้
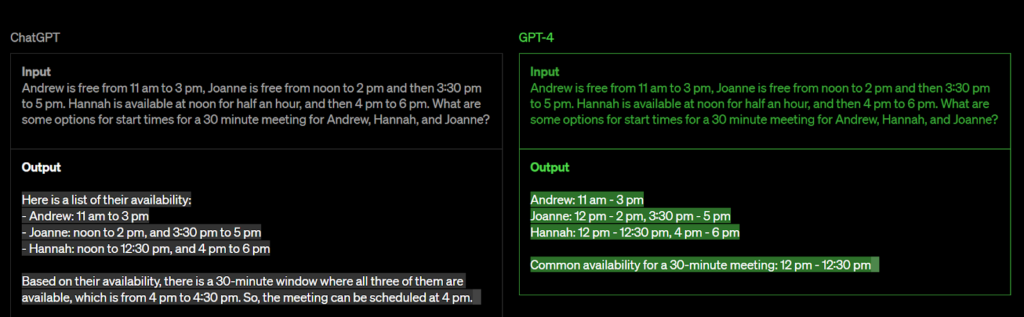
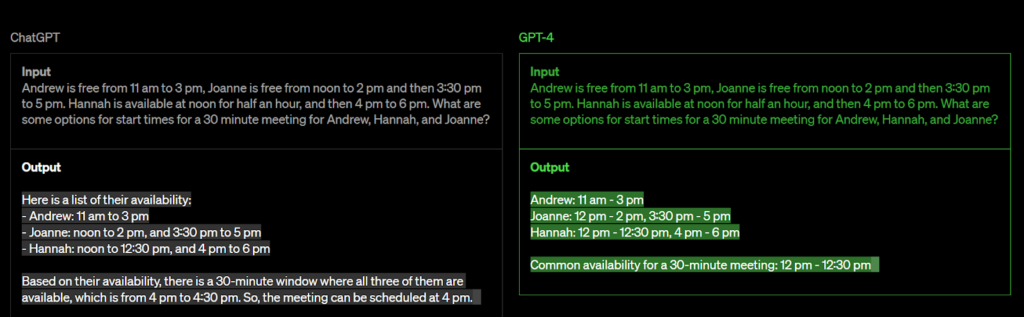
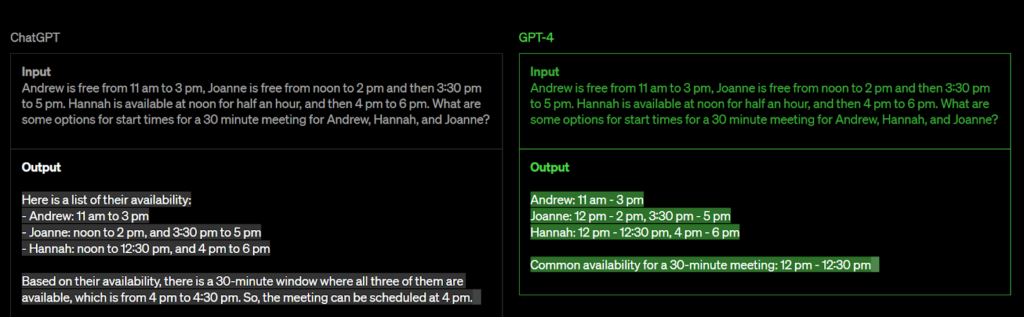
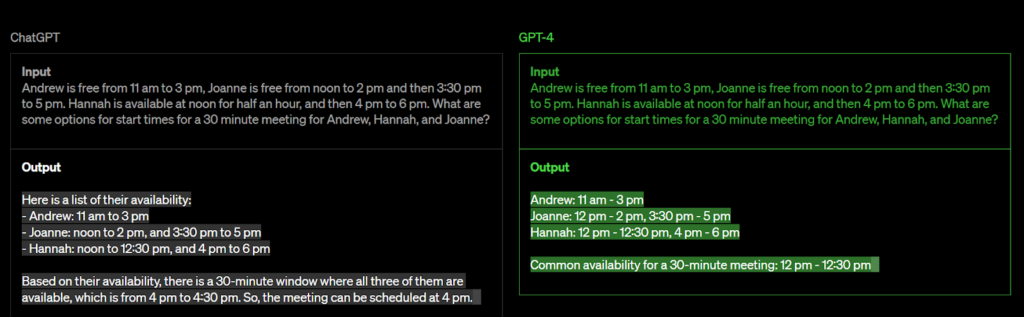
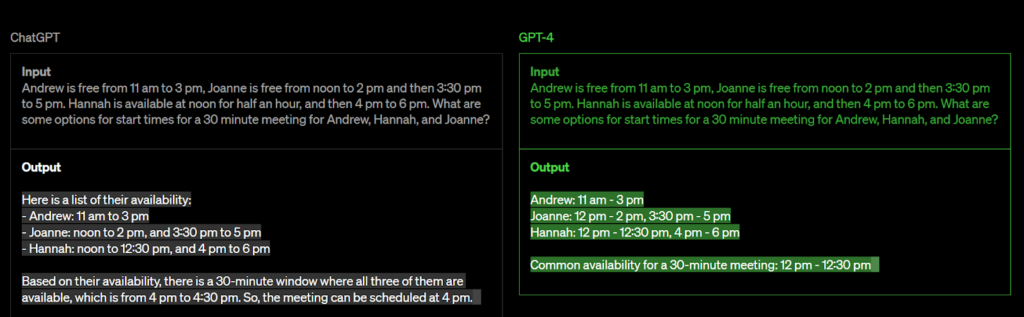
เพื่อให้เข้าใจได้ดีขึ้น ลองพิจารณาตัวอย่าง ChatGPT และ GPT-4
แม้ว่า ChatGPT จะเป็นรูปแบบภาษาที่โดดเด่นซึ่งพิสูจน์แล้วว่ามีประโยชน์อย่างมากในหลายๆ บริบท แต่ก็มีข้อจำกัดบางประการในด้านต่างๆ เช่น การใช้เหตุผลที่ซับซ้อน
เพื่อแก้ไขปัญหานี้ GPT ซ้ำครั้งต่อไป GPT-4 คาดว่าจะเกินความสามารถในการให้เหตุผลของ ChatGPT ด้วยการใช้อัลกอริทึมขั้นสูงมากขึ้นและการผสมผสานหลายรูปแบบ ทำให้ GPT-4 พร้อมที่จะยกระดับการประมวลผลภาษาธรรมชาติไปอีกขั้น ทำให้สามารถจัดการกับปัญหาการใช้เหตุผลที่ซับซ้อนมากขึ้น และปรับปรุงความสามารถในการสร้างการตอบสนองที่เหมือนมนุษย์มากขึ้น
ตัวอย่างบางส่วนของ Multimodal LLMs
OpenAI: GPT-4
GPT-4 เป็นโมเดลหลายรูปแบบขนาดใหญ่ที่สามารถรับทั้งการป้อนรูปภาพและข้อความ และสร้างเอาต์พุตข้อความ แม้ว่า GPT-4 อาจไม่มีความสามารถเท่ามนุษย์ในบางสถานการณ์ในโลกแห่งความเป็นจริง แต่ GPT-4 ได้แสดงประสิทธิภาพในระดับมนุษย์ในเกณฑ์มาตรฐานทางวิชาชีพและวิชาการมากมาย
เมื่อเปรียบเทียบกับรุ่นก่อน GPT-3.5 ความแตกต่างระหว่างสองรุ่นอาจดูเล็กน้อยในการสนทนาทั่วไป แต่จะปรากฏชัดเจนเมื่อความซับซ้อนของงานถึงเกณฑ์ที่กำหนด GPT-4 มีความน่าเชื่อถือและสร้างสรรค์มากกว่า และสามารถจัดการกับคำสั่งที่เหมาะสมกว่า GPT-3.5
นอกจากนี้ยังสามารถจัดการข้อความแจ้งที่เกี่ยวข้องกับข้อความและรูปภาพ ซึ่งช่วยให้ผู้ใช้สามารถระบุวิสัยทัศน์หรืองานด้านภาษาได้ GPT-4 ได้แสดงความสามารถในโดเมนต่างๆ รวมถึงเอกสารที่มีข้อความ รูปถ่าย ไดอะแกรม หรือภาพหน้าจอ และสามารถสร้างเอาต์พุตข้อความ เช่น ภาษาธรรมชาติและรหัส
Khan Academy ได้ประกาศเมื่อเร็ว ๆ นี้ว่าจะใช้ GPT-4 เพื่อพัฒนาผู้ช่วยสอน AI Khanmigo ซึ่งจะทำหน้าที่เป็นติวเตอร์เสมือนจริงสำหรับนักเรียน และเป็นผู้ช่วยในชั้นเรียนสำหรับครู เนื่องจาก ความสามารถของนักเรียนแต่ละคน ในการเข้าใจแนวคิด แตกต่างกันอย่างมาก และการใช้ GPT-4 จะช่วยให้ Khan Academy จัดการกับปัญหานี้ได้
ไมโครซอฟท์: Kosmos-1
Kosmos-1 เป็น Multimodal Large Language Model (MLLM) ที่สามารถรับรู้รูปแบบต่างๆ เรียนรู้ในบริบท (ไม่กี่ช็อต) และทำตามคำสั่ง (zero-shot) Kosmos-1 ได้รับการฝึกอบรมตั้งแต่เริ่มต้นด้วยข้อมูลเว็บ รวมถึงข้อความและรูปภาพ คู่คำบรรยายภาพ และข้อมูลข้อความ
แบบจำลองได้รับประสิทธิภาพที่น่าประทับใจในด้านภาษา
งานด้านความเข้าใจ การสร้าง ภาษาการรับรู้ และการมองเห็น Kosmos-1 รองรับกิจกรรมภาษา ภาษาการรับรู้ และการมองเห็นโดยกำเนิด และสามารถจัดการงานที่ต้องใช้การรับรู้มากและใช้ภาษาธรรมชาติได้
Kosmos-1 ได้แสดงให้เห็นว่าการทำงานหลายรูปแบบช่วยให้โมเดลภาษาขนาดใหญ่บรรลุผลสำเร็จได้มากขึ้นโดยใช้เวลาน้อยลง และช่วยให้โมเดลขนาดเล็กสามารถแก้ปัญหาที่ซับซ้อนได้

Google: PaLM-E
PaLM-E เป็นแบบจำลองหุ่นยนต์ใหม่ที่พัฒนาโดยนักวิจัยที่ Google และ TU Berlin ซึ่งใช้การถ่ายโอนความรู้จากโดเมนภาพและภาษาต่างๆ เพื่อปรับปรุงการเรียนรู้ของหุ่นยนต์ PaLM-E ฝึกโมเดลภาษาเพื่อรวมข้อมูลเซ็นเซอร์ดิบจากตัวแทนหุ่นยนต์โดยตรง ซึ่งแตกต่างจากความพยายามก่อนหน้านี้ ส่งผลให้ได้โมเดลการเรียนรู้ของหุ่นยนต์ที่มีประสิทธิภาพสูง ซึ่งเป็นโมเดลภาษาภาพเพื่อวัตถุประสงค์ทั่วไปที่ล้ำสมัย
โมเดลรับข้อมูลเข้าด้วยข้อมูลประเภทต่างๆ เช่น ข้อความ รูปภาพ และความเข้าใจในสภาพแวดล้อมของหุ่นยนต์ สามารถสร้างการตอบสนองในรูปแบบข้อความธรรมดาหรือชุดคำสั่งที่เป็นข้อความที่สามารถแปลเป็นคำสั่งปฏิบัติการสำหรับหุ่นยนต์ตามประเภทข้อมูลอินพุตที่หลากหลาย รวมถึงข้อความ รูปภาพ และข้อมูลด้านสิ่งแวดล้อม
PaLM-E แสดงให้เห็นถึงความสามารถทั้งในงานที่เป็นตัวเป็นตนและไม่ใช่ตัวเป็นตน ซึ่งเห็นได้จากการทดลองที่ดำเนินการโดยนักวิจัย การค้นพบของพวกเขาบ่งชี้ว่าการฝึกอบรมแบบจำลองเกี่ยวกับการผสมผสานระหว่างงานและรูปแบบต่างๆ จะช่วยเพิ่มประสิทธิภาพในการทำงานแต่ละงาน
นอกจากนี้ ความสามารถของโมเดลในการถ่ายโอนความรู้ช่วยให้สามารถแก้ปัญหางานหุ่นยนต์ได้แม้จะมีตัวอย่างการฝึกอบรมที่จำกัดอย่างมีประสิทธิภาพ นี่เป็นสิ่งสำคัญอย่างยิ่งในวิทยาการหุ่นยนต์ ซึ่งการได้รับข้อมูลการฝึกอบรมที่เพียงพออาจเป็นเรื่องที่ท้าทาย
ข้อจำกัดของ Multimodal LLMs
มนุษย์เรียนรู้และผสมผสานวิธีต่างๆ และวิธีการทำความเข้าใจโลกรอบตัวโดยธรรมชาติ ในทางกลับกัน multimodal LLMs พยายามที่จะเรียนรู้ภาษาและการรับรู้ไปพร้อมๆ กัน หรือรวมส่วนประกอบที่ได้รับการฝึกอบรมไว้ล่วงหน้า แม้ว่าวิธีนี้จะนำไปสู่การพัฒนาที่เร็วขึ้นและความสามารถในการปรับขยายที่ดีขึ้น แต่ก็อาจส่งผลให้เกิดความไม่ลงรอยกันกับสติปัญญาของมนุษย์ ซึ่งอาจแสดงออกมาผ่านพฤติกรรมที่แปลกหรือผิดปกติ
แม้ว่า multimodal LLMs กำลังมีความก้าวหน้าในการแก้ไขปัญหาที่สำคัญบางประการของรูปแบบภาษาสมัยใหม่และระบบการเรียนรู้เชิงลึก แต่ก็ยังมีข้อจำกัดที่ต้องแก้ไข ข้อจำกัดเหล่านี้รวมถึงความไม่ตรงกันที่อาจเกิดขึ้นระหว่างแบบจำลองและความฉลาดของมนุษย์ ซึ่งอาจขัดขวางความสามารถในการเชื่อมช่องว่างระหว่าง AI และความรู้ความเข้าใจของมนุษย์
สรุป: เหตุใด Multimodal LLMs จึงเป็นอนาคต
ขณะนี้เราอยู่ในระดับแนวหน้าของยุคใหม่ในด้านปัญญาประดิษฐ์ และแม้จะมีข้อจำกัดในปัจจุบัน แต่โมเดลหลายรูปแบบก็พร้อมจะเข้ามาแทนที่ โมเดลเหล่านี้รวมประเภทข้อมูลและรูปแบบต่างๆ เข้าด้วยกัน และมีศักยภาพในการเปลี่ยนแปลงวิธีที่เราโต้ตอบกับเครื่องจักรได้อย่างสมบูรณ์
multimodal LLMs ประสบความสำเร็จอย่างน่าทึ่งในด้านคอมพิวเตอร์วิทัศน์และการประมวลผลภาษาธรรมชาติ อย่างไรก็ตาม ในอนาคต เราคาดหวังได้ว่า multimodal LLMs จะมีผลกระทบอย่างมากต่อชีวิตของเรา
ความเป็นไปได้ของ multimodal LLMs นั้นไม่มีที่สิ้นสุด และเราเพิ่งจะเริ่มสำรวจศักยภาพที่แท้จริงของพวกเขาเท่านั้น ด้วยคำสัญญาอันยิ่งใหญ่ของพวกเขา เป็นที่ชัดเจนว่า multimodal LLMs จะมีบทบาทสำคัญในอนาคตของ AI