Google เปิดเผยรายละเอียดหนึ่งในซูเปอร์คอมพิวเตอร์ปัญญาประดิษฐ์ของตน โดยกล่าวว่าเร็วกว่าและมีประสิทธิภาพมากกว่าระบบของ Nvidia ที่กำลังแข่งขันกัน เนื่องจากโมเดลการเรียนรู้ของ AI ต้องใช้พลังงานประมวลผลสูงมาก ยังคงเป็นส่วนที่พัฒนาแข่งขันกันอย่างร้อนแรงที่สุดของอุตสาหกรรมเทคโนโลยี AI
Google published details about one of its artificial intelligence supercomputers on Wednesday, saying it is faster and more efficient than competing Nvidia systems, as power-hungry machine learning models continue to be the hottest part of the tech industry.

ซูเปอร์คอมพิวเตอร์ AI เร็วกว่าและประสิทธิภาพมากกว่าคู่แข่งชิป A100 ของ Nvidia
ในขณะที่ Nvidia ครองตลาดสำหรับการฝึกอบรมและการปรับใช้โมเดล AI โดยกว่า 90% Google ได้ออกแบบและใช้งานชิป AI ที่เรียกว่า Tensor Processing Units หรือ TPUs มาตั้งแต่ปี 2559
Google เป็นผู้บุกเบิกด้าน AI ที่สำคัญ และพนักงานของบริษัทได้พัฒนาความก้าวหน้าที่สำคัญที่สุด หลายประการในสาขา AI ในช่วงทศวรรษที่ผ่านมา แต่บางคนเชื่อว่า บริษัทอาจกำลังตามหลังคู่แข่งในธุรกิจนวัตกรรม AI ดังนั้น ทุกคนภายในบริษัท ต่างพยายามเร่งออกผลิตภัณฑ์ และพิสูจน์ว่าบริษัทไม่ได้สูญเสียความเป็นผู้นำ ซึ่งเป็นสถานการณ์ฉุกเฉิน “code red” ของบริษัท ตามที่ CNBC ได้รายงานไปก่อนหน้านี้

โมเดลและผลิตภัณฑ์ AI เช่น Bard ของ Google หรือ ChatGPT ของ OpenAI ซึ่งขับเคลื่อนโดยชิป A100 ของ Nvidia ต้องใช้คอมพิวเตอร์จำนวนมากและชิปนับร้อยนับพันในการทำงานร่วมกันเพื่อฝึกโมเดล โดยคอมพิวเตอร์จะทำงานตลอดเวลาเป็นเวลาหลายสัปดาห์หรือหลายเดือน
เมื่อวันอังคารที่ผ่านมา Google กล่าวว่าได้สร้างระบบที่มี TPU มากกว่า 4,000 ชิ้น ที่ออกแบบมาเพื่อรันและฝึกโมเดล AI โดยเฉพาะ เริ่มใช้งานมาตั้งแต่ปี 2020 และใช้เพื่อฝึกโมเดล PaLM ของ Google ซึ่งเป็นคู่แข่งขันกับโมเดล GPT ของ OpenAI ในระยะเวลากว่า 50 วัน
ซูเปอร์คอมพิวเตอร์ที่ใช้ TPU ของ Google เรียกว่า TPU v4 นั้น “เร็วกว่า 1.2 – 1.7 เท่า และใช้พลังงานน้อยกว่า Nvidia A100 1.3–1.9 เท่า” นักวิจัยของ Google รายงาน
“ประสิทธิภาพ ความสามารถในการปรับขนาด และความพร้อมใช้งานทำให้ซูเปอร์คอมพิวเตอร์ TPU v4 ตอบโจทย์การใช้งานรองรับ large language models” นักวิจัย แสดงความเห็น
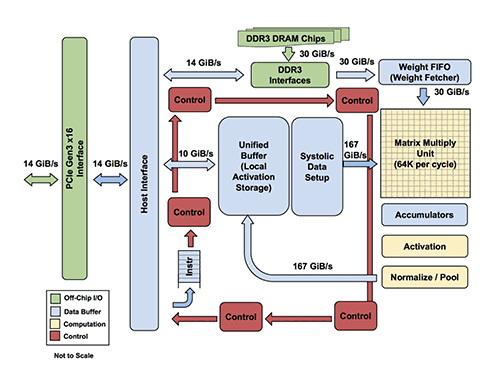
TensorFlow processing unit architecture. Source: Google
อย่างไรก็ตาม ผลลัพธ์ของ TPU ของ Google ไม่สามารถเปรียบเทียบกับชิป Nvidia AI ล่าสุดอย่าง H100 ได้ เนื่องจากเป็นรุ่นล่าสุดกว่าและผลิตด้วยเทคโนโลยีการผลิตขั้นสูงกว่า นักวิจัยของ Google กล่าว
ตามผลลัพธ์การจัดอันดับ จากการทดสอบชิป AI ทั่วทั้งอุตสาหกรรม ที่เรียกว่า MLperf ที่อัพเดตเมื่อวันพุธที่ผ่านมา และ Jensen Huang CEO ของ Nvidia กล่าวว่าผลลัพธ์สำหรับชิป Nvidia ล่าสุดอย่าง H100 นั้นเร็วกว่ารุ่นก่อนหน้าอย่างมาก
“MLPerf 3.0 ของวันนี้เน้นย้ำว่า Hopper ให้ประสิทธิภาพมากกว่า A100 ถึง 4 เท่า” Huang เขียนในบล็อกโพสต์ “Generative AI ในระดับถัดไปต้องการโครงสร้างพื้นฐาน AI ใหม่เพื่อฝึก LLMs ที่มีประสิทธิภาพ มีพลังประมวลผลสูง
การเทรนนิ่งดาต้าเซ็ตของ Generative AI ต้องการพลังประมวลผลของคอมพิวเตอร์สูง จำนวนมาก ที่มีความจำเป็นสำหรับ AI นั้นมีราคาแพง และหลาย ๆ คนในอุตสาหกรรมนี้มุ่งเน้นไปที่การพัฒนาชิปใหม่ ส่วนประกอบต่าง ๆ เช่น การเชื่อมต่อด้วยแสง หรือเทคนิคซอฟต์แวร์ที่ลดปริมาณพลังประมวลผลคอมพิวเตอร์ที่จำเป็น ข้อกำหนดด้านพลังประมวลผลของ AI ยังเป็นประโยชน์ต่อผู้ให้บริการระบบคลาวด์ เช่น Google, Microsoft และ Amazon
ซึ่งสามารถเช่าการประมวลผลของคอมพิวเตอร์ เป็นรายชั่วโมง และให้เครดิต หรือเวลาในการประมวลผลแก่สตาร์ทอัพ เพื่อสร้างความสัมพันธ์ (ระบบคลาวด์ของ Google ยังขายเวลาบนชิป Nvidia ด้วย) ตัวอย่างเช่น Google กล่าวว่า Midjourney โปรแกรมสร้างภาพ AI ที่ได้รับความนิยมอย่างสูง ก็ได้ถูกเทรนผ่านการประมวลผลจากชิป TPU
