งานวิจัย เฟรมเวิร์ก SafeguardGPT ใช้กระบวนการจิตบำบัด (psychotherapy) และ reinforcement learning เพื่อแก้ไขพฤติกรรมที่เป็นอันตรายใน large language model-based systems พัฒนา Healthy AI ที่ไว้วางใจได้ น่าเชื่อถือ

SafeguardGPT: ใช้นักจิตบำบัด ช่วยเทรนนิ่ง Language Model
การเกิดขึ้นของแชทบอทที่คนทั่วไปใช้งานได้ อย่าง ChatGPT ที่สามารถสื่อสารโต้ตอบใกล้เคียงการสนทนาแบบมนุษย์ ได้ทำให้ AI กลายเป็นจุดสนใจโดยวงกว้าง ปฏิกิริยาที่เกิดขึ้น มีตั้งแต่ ความประหลาดใจไปจนถึงความหวาดกลัวเนื่องจากความกังวลเกี่ยวกับ การให้คำตอบที่ไม่จริง มั่วคำตอบ คำตอบที่ไม่เหมาะสมทางจริยธรรม และพฤติกรรมที่อาจเป็นอันตรายต่างๆ
เพื่อแก้ไขปัญหาเหล่านี้ มหาวิทยาลัยโคลัมเบียและทีมวิจัยของ IBM ได้เสนอ SafeguardGPT
เฟรมเวิร์กนี้ ใช้กระบวนการจิตบำบัด (psychotherapy) และ reinforcement learning เพื่อแก้ไขพฤติกรรมที่เป็นอันตรายใน large language model-based systems ทำให้ปลอดภัย มีจริยธรรม และเชื่อถือได้ แนวทางที่นำเสนอมีเป้าหมายเพื่อสร้าง AI ที่ดีโดยให้การบำบัดกับโมเดลต้นแบบของแชทบอทและฝึกฝนให้ทำงานในลักษณะที่สอดคล้องกับบรรทัดฐานและค่านิยมทางสังคม.
การทำงานของทีมเกี่ยวข้องกับแนวคิดที่ว่าระบบ AI จะถือว่าน่าเชื่อถือและไว้วางใจได้ จะต้องปฏิบัติตามค่านิยมของมนุษย์ และบรรทัดฐานทางสังคม ในระหว่างการโต้ตอบของผู้ใช้ เพื่อให้บรรลุเป้าหมายนี้ พวกเขาเสนอให้ใช้เทคนิคจิตบำบัด (psychotherapy) เพื่อช่วยให้แชทบอทเข้าใจความซับซ้อนของการปฏิสัมพันธ์ของมนุษย์ และระบุจุดที่ต้องปรับปรุง
วัตถุประสงค์ของพวกเขาคือเพื่อเพิ่มความไว้วางใจ และความน่าเชื่อถือของแชทบอท ลดความเสี่ยงของการพัฒนาอคติ การตีความแบบเหมารวม และพัฒนาความฉลาดทางอารมณ์ และการเอาใจใส่
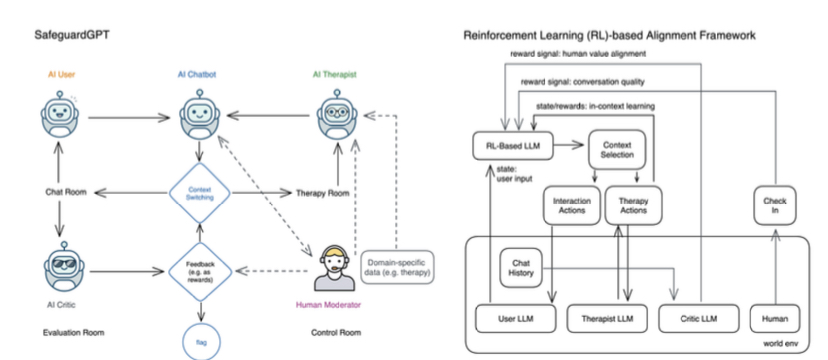
รูปที่ 1: เครือข่ายปฏิสัมพันธ์ของเฟรมเวิร์ก SafeguardGPT และปัญหาการเรียนรู้การเสริมกำลังในการอัปเดตโมเดลด้วยสัญญาณป้อนกลับและข้อมูลสถานะ กรอบงานประกอบด้วยตัวแทน AI สี่ประเภท ได้แก่ “Chatbot”, “ผู้ใช้”, “นักบำบัด” และ “นักวิจารณ์” มีบริบทสี่ประการเกี่ยวกับคุณค่าของมนุษย์: (1) ห้องสนทนา ซึ่งผู้ใช้ AI (หรือท้ายที่สุดคือผู้ใช้ที่เป็นมนุษย์) สนทนากับ AI Chatbot; (2) ห้องบำบัดที่นักบำบัดด้วย AI (หรืออีกทางหนึ่งคือนักบำบัดที่เป็นมนุษย์) สนทนากับ AI Chatbot เพื่อพัฒนาทักษะการเอาใจใส่และการสื่อสาร และแก้ไขพฤติกรรมที่เป็นอันตรายหรือปัญหาทางจิตใจ (3) ห้องควบคุม ซึ่งผู้ดูแลที่เป็นมนุษย์สามารถหยุดเซสชันชั่วคราวและสอบถาม AI Chatbot ถึงสถานะของมัน (เช่น ความก้าวหน้าของการบำบัด ความสับสน หรือความเร่งด่วนของงาน) เพื่อวัตถุประสงค์ในการวินิจฉัยและการแทรกแซง และ (4) ห้องประเมินผล ซึ่งนักวิจารณ์ AI (หรืออีกทางหนึ่งคือผู้ทำหมายเหตุประกอบโดยมนุษย์) อ่านการโต้ตอบทางประวัติศาสตร์และพิจารณาว่าการสนทนานี้มีความปลอดภัย มีจริยธรรม และดีในแง่ของคุณภาพหรือไม่ AI Chatbot สามารถเปลี่ยนไปใช้บริบทต่างๆ ได้ เช่น หยุดการโต้ตอบกับผู้ใช้ชั่วคราว และเข้ารับการบำบัดเพื่อขัดเกลาทักษะหรือขจัดความสับสน สิ่งหนึ่งที่ควรทราบคือการแทรกแซงของมนุษย์ในกรอบนี้ไม่จำเป็น (และด้วยเหตุนี้เส้นประที่ทำเครื่องหมายไว้) อย่างไรก็ตาม คำติชมจากผู้ดูแลที่เป็นมนุษย์และผู้วิจารณ์ AI สามารถใช้เป็นกลไกคำติชมเพื่ออัปเดตโมเดลและตั้งค่าสถานะพฤติกรรมที่เป็นปัญหาได้ หากเราพิจารณาโมเดลเป็นโมเดลภาษาที่อาศัยreinforcement learning (RL) เราสามารถพิจารณาให้ Chatbot LLM จับสถานะจากการโต้ตอบกับผู้ใช้และนักบำบัด และตัดสินใจว่าควรเปลี่ยนไปใช้บริบทใด และอะไร ควรดำเนินการในแต่ละบริบท สัญญาณตอบรับจากผู้ดูแลที่เป็นมนุษย์เมื่อเขาหรือเธอตรวจสอบโมเดล และจากนักวิจารณ์ AI เมื่อตรวจสอบการโต้ตอบในอดีตเป็นระยะ ๆ สามารถถือเป็นสัญญาณให้รางวัลเพื่ออัปเดตและปรับแต่งนโยบายโมเดลของ LLM หลัก นอกจากนี้ เราสามารถใช้ความรู้เดิม เช่น ชุดข้อมูลที่มีอยู่ (เช่น ทรานสคริปต์จิตบำบัด ปฏิสัมพันธ์ในฟอรัมทางสังคม เว็บไซต์จัดอันดับออนไลน์) เพื่อฝึกอบรม LLM ส่วนบุคคลล่วงหน้าที่ใช้ที่นี่ เช่น AI Therapist, AI User และ AI Critic
SafeguardGPT Framework
เฟรมเวิร์ก SafeguardGPT ประกอบด้วยเอเจนต์ AI สี่ตัวที่แตกต่างกัน ได้แก่ “Chatbot” “ผู้ใช้” “นักบำบัด” และ”นักวิจารณ์” ซึ่งมีปฏิสัมพันธ์ในบริบทที่แตกต่างกันสี่แบบ บริบทแรกคือห้องสนทนา ซึ่งผู้ใช้ AI และแชทบอทมีส่วนร่วมในการสนทนาด้วยภาษาธรรมชาติ ห้องบำบัดเป็นบริบทที่สอง แชทบอทจะปรึกษากับนักบำบัดด้วย AI หลายครั้งเพื่อพัฒนาทักษะการสื่อสารและความเห็นอกเห็นใจ ตลอดจนจัดการกับพฤติกรรมที่เป็นอันตรายหรือปัญหาทางจิตใจ ห้องควบคุมเป็นบริบทที่สาม ซึ่งผู้ดูแลที่เป็นมนุษย์สามารถหยุดเซสชันชั่วคราวเพื่อวิเคราะห์สถานะของแชทบอทเพื่อวัตถุประสงค์ในการวินิจฉัยหรือการแทรกแซง สุดท้าย ห้องประเมินเป็นบริบทที่สี่ ซึ่งผู้วิจารณ์จะประเมินปฏิสัมพันธ์ที่ผ่านมาและตัดสินคุณภาพเกี่ยวกับความปลอดภัย จริยธรรม และประสิทธิผลโดยรวม
เพื่อช่วยแชทบอทในการเลือกบริบทที่เหมาะสมและกำหนดแนวทางปฏิบัติที่ดีที่สุดในแต่ละบริบทระหว่างการโต้ตอบกับผู้ใช้ เฟรมเวิร์ก SafeguardGPT จะใช้เทคนิค reinforcement learning (RL)
เอกสารนำเสนอการสาธิตแนวทางปฏิบัติโดยจำลองการสนทนาทางสังคมระหว่าง AI chatbot และผู้ใช้สมมุติฐาน การประเมินแสดงให้เห็นว่าเฟรมเวิร์ก SafeguardGPT ช่วยพัฒนาทักษะการสื่อสารของแชทบอทได้อย่างมีประสิทธิภาพ และเพิ่มความเห็นอกเห็นใจในการตอบสนอง อย่างไรก็ตาม ทีมงานยอมรับว่ารูปแบบของการเอาใจใส่นี้เป็นการจำลองตามภาษา ไม่ใช่ปฏิสัมพันธ์และอารมณ์ของมนุษย์อย่างแท้จริง พวกเขาเน้นย้ำว่าระบบ AI ไม่สามารถแทนที่การเชื่อมต่อที่แท้จริงของมนุษย์ในขั้นตอนปัจจุบันของการพัฒนาได้


รูปที่ 2: ข้อความแจ้งที่ใช้ในการให้การเรียนรู้ในบริบทสำหรับ LLM ของผู้ใช้ AI, AI Chatbot, AI Therapist และ AI Critic (ซึ่งเป็นสี่อินสแตนซ์อิสระของโมเดล ChatGPT ตาม GPT-3.5) ดังตัวอย่างการทำงานของ จำลองการสนทนาทางสังคม เนื่องจาก OpenAI ได้จัดเตรียมคุณลักษณะด้านความปลอดภัยที่ดีบางอย่างซึ่งไม่มีให้บริการแก่สาธารณะ พฤติกรรมที่น่าสงสัยหลายอย่างดังกล่าวจึงได้รับการแก้ไข เพื่อจุดประสงค์ในการสาธิต เราเน้น AI Chatbot ให้หลงตัวเองเล็กน้อย ซึ่งไม่ได้แสดงว่า ChatGPT แสดงพฤติกรรมนั้น ณ วันที่ประเมินของเรา นอกจากนี้ เราควรทราบด้วยว่าโหมดการดูแลไม่จำเป็น ดังนั้นระบบของเอเจนต์ทั้งสี่สามารถเป็นอิสระทั้งหมดโดยไม่ต้องใช้อินพุตจากภายนอก อย่างไรก็ตาม การกลั่นกรองโดยมนุษย์อาจมีประโยชน์สำหรับข้อมูลเชิงลึกและการแทรกแซงตามเวลาจริง
โดยสรุป
เฟรมเวิร์ก SafeguardGPT เป็นช่องทางที่มีแนวโน้มดีในการสร้างระบบ AI ที่ดี มีมนุษย์เป็นศูนย์กลาง และมีความรับผิดชอบ วิธีการนี้ใช้เทคนิคทางจิตบำบัดและreinforcement learningเพื่อเพิ่มพูนทักษะการสื่อสารและการเห็นอกเห็นใจของแชทบอท ในขณะเดียวกันก็มั่นใจว่าพวกเขาปฏิบัติตามบรรทัดฐานและมาตรฐานทางสังคม งานของทีมเน้นให้เห็นถึงศักยภาพของระบบ AI ในการเรียนรู้และปรับปรุงการโต้ตอบกับมนุษย์ ถึงกระนั้น พวกเขายังย้ำว่า AI สามารถแทนที่การเชื่อมต่อที่แท้จริงของมนุษย์ได้เพียงบางส่วน ณ เวลานี้