อาลีบาบา บริษัทการค้าข้ามชาติของจีน ซึ่งเป็นที่รู้จักดีที่สุดในด้านอีคอมเมิร์ซ ก็ลงทุนอย่างมากในโครงการพัฒนาเทคโนโลยีใหม่ นักวิจัยในสถาบันคอมพิวเตอร์อัจฉริยะของบริษัทได้สาธิต EMO ซึ่งเป็นเครื่องมือสร้างวิดีโอ AI video generator ตัวใหม่ของพวกเขา
Chinese multinational Alibaba, best known for its e-commerce operations, also heavily invests in technological development projects. Researchers in the company’s Institute for Intelligent Computing showed off their new AI video generator, EMO.

EMO เครื่องมือสร้างวิดีโอ AI ใหม่ของอาลีบาบาทำให้รูปภาพพูดและร้องเพลงได้
อาลีบาบา บริษัทการค้าข้ามชาติของจีน ซึ่งเป็นที่รู้จักดีที่สุดในด้านอีคอมเมิร์ซ ก็ลงทุนอย่างมากในโครงการพัฒนาเทคโนโลยีใหม่ นักวิจัยในสถาบันคอมพิวเตอร์อัจฉริยะของบริษัทได้สาธิต EMO ซึ่งเป็นเครื่องมือสร้างวิดีโอ AI video generator ตัวใหม่ของพวกเขา
EMO หรือ Emote Portrait Alive คือ expressive audio-driven portrait-video generation framework เฟรมเวิร์กการสร้างวิดีโอด้วย AI ซึ่งเปลี่ยนภาพนิ่ง และเสียงร้อง ที่เราต้องการ ให้เป็น animated avatar video แปลงให้ภาพนิ่งกลายเป็นวิดีโอเคลื่อนไหวได้ ที่สามารถแสดงออกทางสีหน้า และท่าทาง ให้สอดคล้องกับการลิปซิงค์กับเสียงร้องเพลง
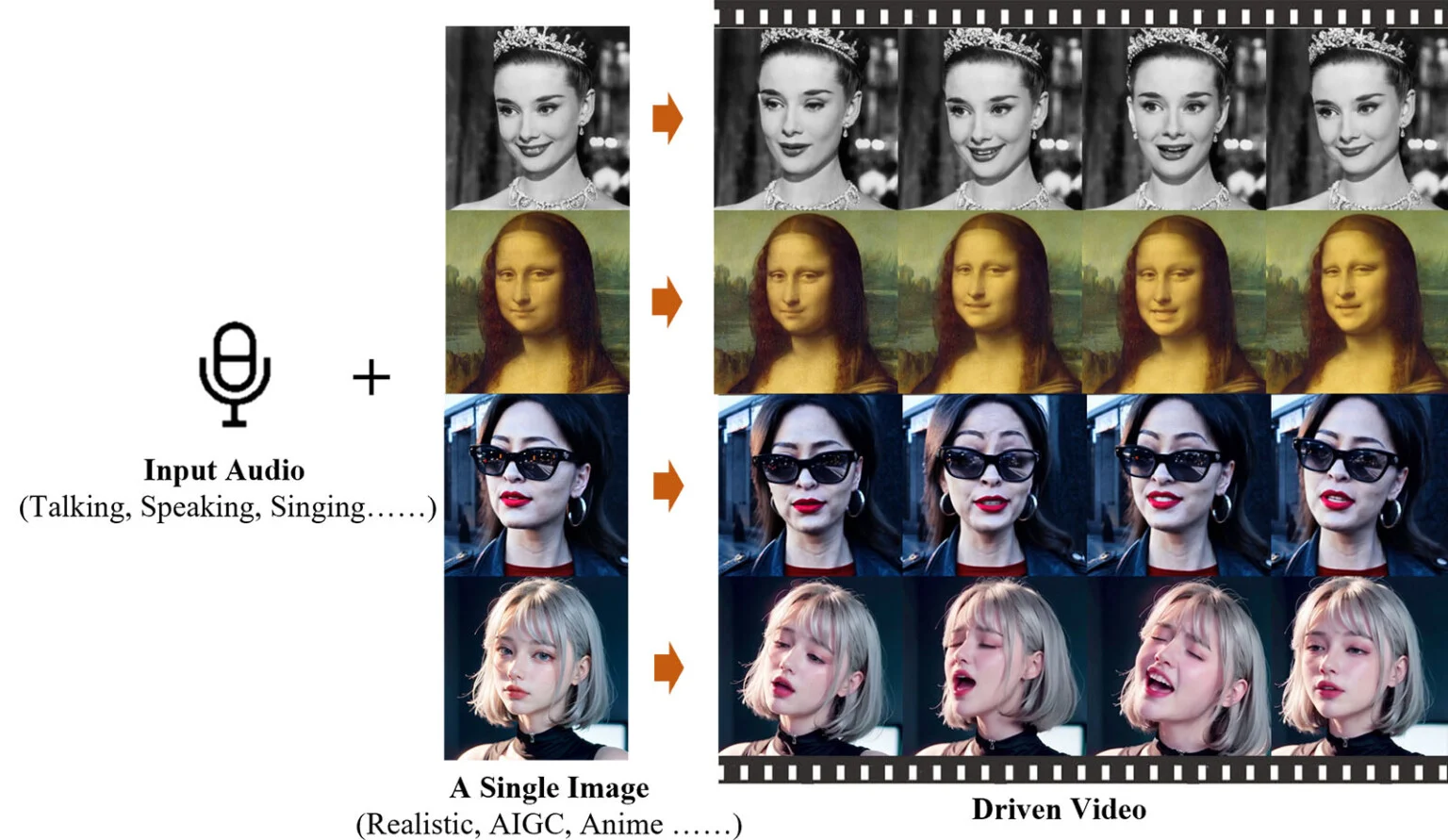
หนึ่งในตัวอย่างที่ทีมสร้างขึ้น คือ การนำผู้หญิงที่สวมแว่นกันแดดที่สร้างโดย AI จากการเปิดตัว Sora ของ OpenAI และให้เธอร้องเพลง “Don’t Start Now” โดย Dua Lipa โชคดีที่ตัวละครตัวนี้เป็นหนึ่งในผลงานการสร้างสรรค์ของ Sora ที่น่ากลัวน้อยที่สุด
อีกตัวอย่างหนึ่ง แสดงภาพถ่าย Mona Lisa ของ da Vinci ที่สร้างโดย AI และให้เธอร้องเพลง “flowers” โดย Miley Cyrus ร้องโดย YUQI อีกคลิปหนึ่ง Audrey Hepburn ร้องเพลงคัฟเวอร์เพลงของ Ed Sheeran โดยช่อง YouTube RINKI ได้รวบรวมคลิปสาธิตทั้งหมดของ Alibaba และอัปเกรดเป็น 4K
ส่วนสำคัญของ EMO ก็คือสามารถทำลิปซิงค์ ให้ริมฝีปากในคลิปวิดีโอสังเคราะห์สอดคล้องกับเสียงร้องเพลงได้ ที่สำคัญคือ โมเดลนี้รองรับเพลงในหลายภาษา นอกจากนี้ยังใช้งานได้กับสไตล์ศิลปะมากมาย ไม่ว่าจะเป็นภาพถ่าย ภาพวาด หรือการ์ตูนสไตล์อนิเมะ นอกจากนี้ยังใช้งานได้กับอินพุตเสียงอื่นๆ เช่น คำพูดทั่วไป
ตามทฤษฎีแล้ว อินพุตเสียงไม่จำเป็นต้องเป็น “เสียงจริง” เช่นกัน สัปดาห์นี้ Adobe ได้เปิดตัวแพลตฟอร์ม generative AI ใหม่ที่สามารถสร้างเพลงจาก text prompt ได้ ซึ่งแน่นอนว่า คนดังอย่าง Taylor Swift จะมีคนใช้ generative AI สร้างเสียงเลียนแบบ ที่ฟังดูสมจริงได้ง่ายมาก
โมเดลที่สร้างขึ้นบน Stable Diffusion backbone นี่ไม่ใช่โมเดลแรกในประเภทนี้ แต่อาจมีประสิทธิภาพมากที่สุด ยังมีความไม่สมบูรณ์ที่เห็นได้ชัดเจน ในการสาธิตครั้งแรกนี้ รวมถึงความยังไม่สมจริงของผิวหนัง และบางครั้ง การลิปซิงค์ของปาก มีการสั่นสะเทือนแปลกๆ อย่างไรก็ตาม ความแม่นยำโดยรวมของการเคลื่อนไหวของริมฝีปากเพื่อตอบสนองต่อเสียงอินพุตนั้นน่าทึ่งมาก
งานวิจัยฉบับสมบูรณ์ของสถาบันคอมพิวเตอร์อัจฉริยะอาลีบาบาได้รับการเผยแพร่บน Github และรายงานการวิจัยที่เกี่ยวข้องมีอยู่ใน ArXiv